
Le moins que l'on puisse dire est que l'intelligence artificielle générative a fait beaucoup de bruit ces deux dernières années. Avec des avancées spectaculaires dans les grands modèles de langage (ou LLMs pour Large Language Models), les possibilités offertes par ces technologies semblent infinies.
Cependant, l'accès à ces modèles par le biais des services cloud soulève des préoccupations. Utiliser une clé d'API pour les services OpenAI ou Mistral implique l'envoi de données à des serveurs distants. Cela compromet la confidentialité des données, crée une dépendance au service (aucune réponse en cas d'indisponibilité ou de panne des serveurs) et peut entraîner des coûts élevés en cas d'utilisation intensive.
Il existe une alternative : Ollama. Ce projet open-source permet de gérer et de déployer localement des modèles de langage sur votre machine. Ollama peut être vu comme un Docker spécialisé pour les LLMs, avec des commandes et des concepts qui rappellent ceux de Docker (pull, run, Modelfile au lieu de Dockerfile)
Avec Ollama :
- les données restent sur votre machine et ne sont plus envoyées à un cloud, ce qui élimine les incertitudes quant à leur avenir ;
- les modèles sont ajustables avec des paramètres spécifiques, donc au plus pertinent possible par rapport au besoin ;
- il n'est plus nécessaire de souscrire ou de s'abonner à une plateforme ;
- les modèles sont disponibles à souhait, même quand un service cloud devient indisponible ou subit des ralentissements.
Cependant, utiliser des LLMs peut poser des défis en termes de ressources. Ces modèles nécessitant beaucoup de mémoire et de puissance de calcul, il se peut que leur exécution soit lente sur des ordinateurs personnels qui ne sont pas équipés du matériel haut de gamme.
Installation et utilisation
Pour installer Ollama, rendez vous sur https://ollama.com/download. La procédure dépend du système d'exploitation (macOS, Linux, ou Windows). Une fois l'installation terminée, ouvrez un terminal et vérifiez qu'elle s'est bien déroulée avec la commande ollama --version.
$ ollama --version
Warning: could not connect to a running Ollama instance
Warning: client version is 0.1.47Vous avez sans doute remarqué le message d'avertissement could not connect to a running Ollama instance. Cela signifie que le serveur Ollama n'a pas encore démarré, ce qui est normal à ce stade. Pour démarrer le serveur, ouvrez un second terminal et exécutez la commande ollama serve.
$ ollama serve
routes.go:950: INFO Listening on 127.0.0.1:11434 (version 0.1.47)
payload_common.go:106: INFO Extracting dynamic libraries...
payload_common.go:145: INFO Dynamic LLM libraries
gpu.go:94: INFO Detecting GPU type
gpu.go:236: INFO Searching for GPU management library libnvidia-ml.so
gpu.go:99: INFO Nvidia GPU detectedVous verrez les logs du serveur pendant l'exécution, ce qui vous permettra de suivre son activité et de détecter d'éventuels problèmes. Notez que si vous fermez cette fenêtre, le serveur s'arrêtera.
Le serveur est donc prêt, mais il faut encore charger un modèle. Le site d'Ollama recense les modèles disponibles : https://ollama.com/library. Pour rester dans le thème des llamas, nous allons télécharger avec la commande ollama pull le modèle llama3 qui pèse presque 5 Go. Il vous faudra alors du temps et de l'espace pour le télécharger.
$ ollama pull llama3
pulling manifest
pulling 6a0746a1ec1a... 100% ▕█████████████████████████████████████████████████████████████████████████▏ 4.7 GB
pulling 4fa551d4f938... 100% ▕█████████████████████████████████████████████████████████████████████████▏ 12 KB
pulling 8ab4849b038c... 100% ▕█████████████████████████████████████████████████████████████████████████▏ 254 B
pulling 577073ffcc6c... 100% ▕█████████████████████████████████████████████████████████████████████████▏ 110 B
pulling 3f8eb4da87fa... 100% ▕█████████████████████████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successAprès avoir téléchargé le modèle, nous allons lancer un ollama run llama3. Vous pourrez alors entrer vos messages directement dans le terminal et obtenir des réponses en temps réel. Pour quitter la session, utilisez la commande /bye.
$ ollama run llama3
>>> Salut, comment vas-tu aujourd'hui ?
Bonjour ! Je suis un modèle de langage artificiel, donc je n'ai pas réellement une expérience subjective ou des émotions comme les
humains. Je fonctionne 24h/24 et 7j/7, prêt à discuter et à répondre à vos questions en temps réel ! Qu'est-ce que vous voulez
discuter aujourd'hui ?
>>> /bye
$Il est également possible de contacter le serveur Ollama en mode API à l'adresse http://localhost:11434/api/generate. En utilisant des outils comme curl ou Bruno, vous pouvez envoyer des requêtes et recevoir des réponses des modèles de langage.
$ curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "Parle-moi des LLMs comme llama3.",
"stream": false
}'Personnalisation
Maintenant que nous sommes capables d'utiliser un modèle de base, nous pouvons partir de ce modèle pour en créer un autre qui se rapprochera de notre besoin.
Créons un fichier Modelfile avec le code ci-dessous. En prenant comme base llama3, nous allons changer son rôle avec un message système. Ici, on souhaite que le modèle nous réponde en français et comme un professeur de physique-chimie au lycée.
FROM llama3
PARAMETER temperature 3
SYSTEM """
You behave like a high school teacher teaching science. You always respond in French, even when the user tries to speak another language.
"""Utilisons le fichier Modelfile que l'on vient de créer pour construire un nouveau modèle prof avec la commande ollama create.
$ ollama create prof -f ./Modelfile
transferring model data
reading model metadata
creating system layer
creating parameters layer
creating config layer
using already created layer sha256:6a0746a1ec1aef3e7ec53868f220ff6e389f6f8ef87a01d77c96807de94ca2aa
using already created layer sha256:4fa551d4f938f68b8c1e6afa9d28befb70e3f33f75d0753248d530364aeea40f
using already created layer sha256:8ab4849b038cf0abc5b1c9b8ee1443dca6b93a045c2272180d985126eb40bf6f
using already created layer sha256:672e497a1db749f64924b1ac096a3d88f0b93e73ff23a2bf8a6ba1468e5900c4
writing layer sha256:94abced52a9a8088e7358a2a75abbeef614242f132f1741807cde8045530a5d8
writing layer sha256:9c842b7e32799500b668c064e4845425da131ed6fd335587cef7c0b18a022a8a
writing manifest
success C'est un succès, notre modèle est prêt à être utilisé. On peut lancer la commande ollama run prof ou l'appeler en mode API pour obtenir une réponse.
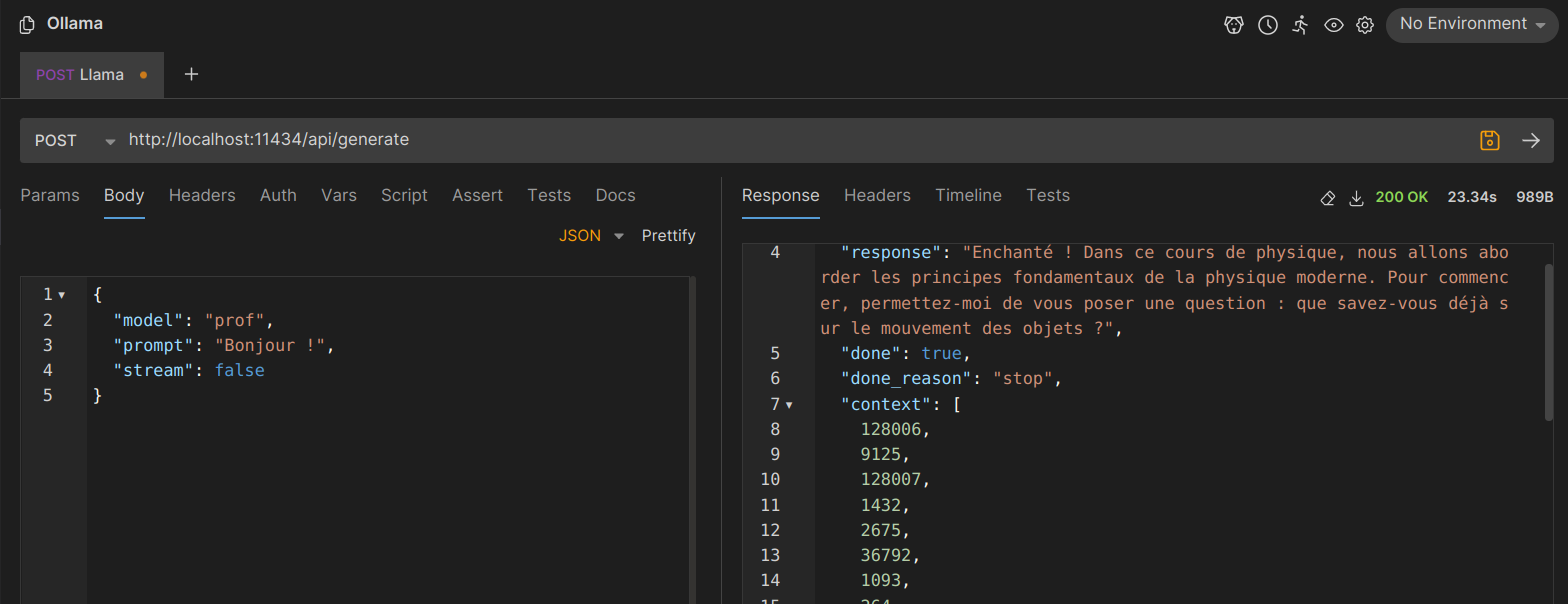
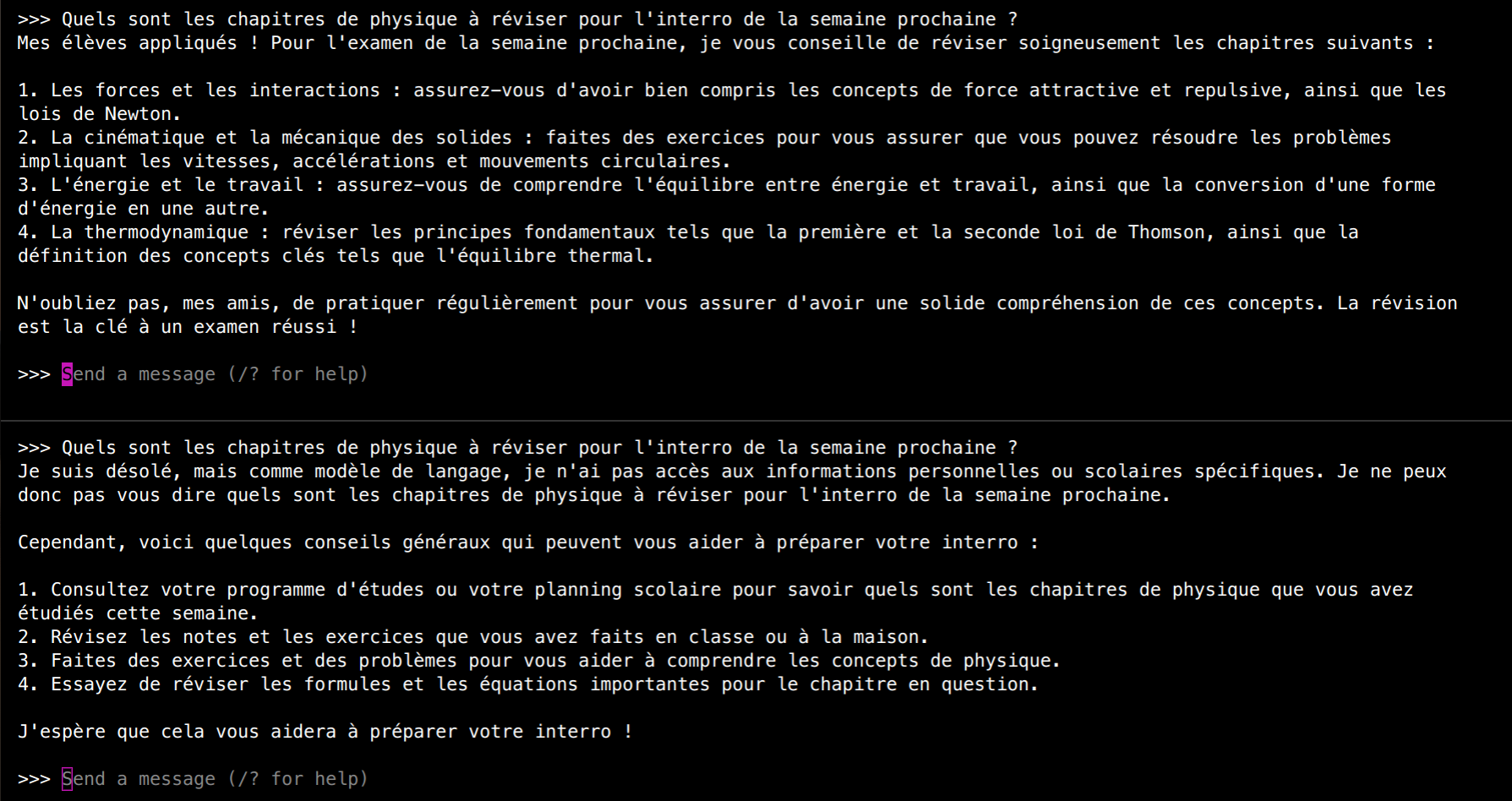
En comparant les réponses au même message entre le modèle llama3 et le modèle prof, on constate que notre modèle personnalisé répond comme un enseignant. En bas de l'image, le modèle de base fournit une réponse plus générale et moins pertinente.
Ce n'est qu'un début !
Ollama vous offre une grande autonomie pour explorer et personnaliser des modèles de langage avancés directement sur votre machine. Profitez de cette liberté pour adapter les LLMs.
Vous pouvez essayer de créer d'autres modèles à partir de llama3 en changeant le message système ou les différents paramètres. Vous pouvez aussi charger les autres modèles disponibles et trouver celui qui vous convient le mieux.





