
La conférence CloudNord 2024, qui s'est tenue à Lille le 10 octobre dernier, a réuni des experts et passionnés du cloud pour une journée d’échanges, d’innovations technologiques et de débats autour des défis du cloud computing. Revenons sur les moments forts et les enseignements clés de cet événement majeur.
Talos chez Ubisoft : serveurs de jeux & plateforme Serverless
Dans le monde en constante évolution des technologies de l'information, les systèmes d'exploitation jouent un rôle crucial. Talos Linux, une distribution Linux minimaliste et immuable, se distingue par son approche innovante et sa focalisation exclusive sur Kubernetes. Écrit en Go, Talos Linux fonctionne entièrement à travers des API, éliminant ainsi les interactions traditionnelles comme SSH. Cet article explore en profondeur le fonctionnement de Talos Linux, ses interactions avec Kubernetes, et ses applications pratiques.
Talos Linux : Une Distribution minimaliste
Talos Linux se démarque par sa simplicité et son minimalisme. Contrairement aux distributions Linux traditionnelles, Talos n'offre pas d'accès SSH. Toutes les interactions se font via une API, ce qui renforce la sécurité et la gestion centralisée.
Une Architecture écrite en Go
L'ensemble de Talos Linux est écrit en Go, un langage de programmation moderne connu pour sa performance et sa simplicité. Cette décision architecturale permet à Talos de bénéficier de la robustesse et de l'efficacité de Go, tout en facilitant la maintenance et l'évolution du code.
Un système immuable
Talos Linux est conçu comme une distribution immuable. Cela signifie que le système d'exploitation n'est pas mis à jour de manière traditionnelle. Au lieu de cela, une nouvelle version est installée sur une partition distincte, permettant un retour en arrière facile en cas de problème. Ce système de partition A/B assure une haute disponibilité et une résilience accrue.
Le Control Plane de Talos Linux
Le control plane de Talos Linux est l'élément central de son architecture. Il s'agit des API de pilotage qui permettent de gérer et de contrôler le système. Tout comme le control plane de Kubernetes accessible via kubectl, le système Talos est pilotable uniquement par API, avec le CLI talosctl.
Gestion des configurations
Les configurations dans Talos Linux sont modifiées via un système de patch partition. Ce mécanisme permet d'appliquer des mises à jour et des modifications de manière atomique, réduisant ainsi les risques d'erreurs et de corruption de données. Les mises à jour de version se font via talosctl, avec la possibilité de rollback en cas de besoin.
Talos Linux et Kubernetes
Talos Linux est conçu spécifiquement pour Kubernetes. Tout tourne dans un conteneur au sein de Talos, et la distribution ne comprend que 12 binaires, ce qui en fait une solution extrêmement légère et performante pour les environnements Kubernetes.
Création de services serverless
L'un des cas d'utilisation de Talos Linux est la création de services serverless via des appels API. Par exemple, en utilisant Postman, il est possible de créer un service qui génère des images par inférence. Cette approche permet de déployer rapidement et efficacement des services sans avoir à gérer l'infrastructure sous-jacente.
Importance de la latence dans les serveurs de jeu
La latence est un facteur critique dans les serveurs de jeu. Une connexion directe et rapide entre les joueurs et les serveurs est essentielle pour une expérience de jeu fluide. Google et Ubisoft ont collaboré pour offrir un service d'hébergement de serveurs de jeux dans Kubernetes, nommé Agones.
Kubernetes Hybride
Le modèle hybride de Kubernetes permet d'avoir des nœuds système dans le cloud public et des machines puissantes qui hébergent des pods de serveurs de jeu. Les joueurs se connectent directement à ces pods, réduisant ainsi la latence et améliorant la performance globale.
☁️ 20 000 nuages sous les mers ☁️
Cette conférence a mis en lumière l'importance cruciale des câbles sous-marins dans le transfert de données à l'échelle mondiale. Actuellement, 99 % du flux de données international transite par ces câbles, qui comptent environ 450 câbles actifs et une centaine en construction, totalisant 1,4 million de kilomètres, soit 35 fois le tour de la Terre.
Le saviez-vous ? Le premier essai de câble télégraphique a eu lieu en 1851 entre Calais et l'Angleterre, mais ce n'est qu'en 1858 qu'un message de 98 caractères a été transmis entre l'Irlande et Terre-Neuve en 17 heures.
Les enjeux politiques et économiques autour des câbles sous-marins sont énormes. En effet, certaines zones isolées du globe sont parfois dépendantes d'un seul câble, à titre d'exemple : les communications entre l'Afrique et l'Amérique du Sud doivent principalement transiter par l'Europe et les USA.
L'état français a racheté 80 % d'Alcatel Submarine Networks (fabricant de câbles) à Nokia. Sachant que ces câbles (1,4 million de kilomètres) ont une durée de vie de 25 ans, la question environnementale se pose également, les câbles décommissionnés étant laissés sur le fond.
Facebook, Microsoft, Amazon et Google se sont notamment lancés dans la bataille pour les câbles sous-marins. Mais qu'en est-il d'Apple ?
Carte des câbles : https://www.submarinecablemap.com/
Ma startup a grossi : quand les fondateurs CTO partent et que les principal engineers arrivent
Nicolas et Théotime (Principal Engineers chez BackMarket) nous partagent les enjeux et les difficultés des métiers de Principal/Staff Engineers, apparus ces dernières années dans nos organisations.
Leur mission principale (si ils l'acceptent 🕵️) est d'anticiper les besoins futurs de l'entreprise, tout en facilitant et accompagnant les développeuses et développeurs peu importe la place des équipes dans l'organigramme. Ils servent de relais entre les équipes et les C-levels et propagent la vision technique du CTO en agissant sur le terrain auprès des équipes.
Vous voulez en savoir plus, je vous conseille le blog de Nicolas qui relate sa première année chez BackMarket.

Comment ingérer 100 milliards d'événements depuis des millions d'appareils par mois ?
Sur scène, Erwan et Valentin de Pubstack (startup spécialisée dans la collecte de données publicitaires en ligne) nous ont présenté leur infrastructure entièrement serverless sur AWS.
Grâce uniquement à des Lambda functions, aux services Kinesis et Firehose, leur petite équipe de développeurs a réussi à mettre en place un pipeline complet capable de produire des données historiques sur plusieurs années, avec scalabilité, robustesse et sécurité. Le tout est stocké dans un Data Lake pour l'historisation et un Data Mart pour les besoins d'analyse immédiate.
Bien entendu, des services essentiels comme S3 pour le stockage cloud ou Identity Access Management (IAM) pour la gestion des droits sont utilisés, mais l'ensemble reste simple et 100 % serverless : pas de SSH vers des machines virtuelles, pas de gestion de serveurs, ni de mise à jour de bases de données.
Un bel exemple de stack technique efficace et performante, avec un coût mensuel maîtrisé. Le sujet du vendor lock-in, bien entendu, sera également abordé pendant la conférence.
Container & security
Avec l'adoption croissante des containers dans les environnements cloud-native, la sécurité est devenue une préoccupation majeure. Les containers offrent une flexibilité et une portabilité sans précédent, mais ils introduisent également de nouveaux vecteurs de menaces. Cet article explore les bonnes pratiques pour sécuriser vos containers, en mettant l'accent sur des concepts clés tels que les "capabilities", les "Golden Images", et les politiques de sécurité Kubernetes.
Ne pas exécuter les processus en Root
L'une des règles de base de la sécurité des containers est de ne jamais exécuter les processus en tant que root. Exécuter un processus en root dans un container donne trop de pouvoir à ce processus. En cas de compromission, cela pourrait permettre à un attaquant de causer des dommages considérables, non seulement au container lui-même, mais aussi potentiellement à l'hôte.
Comprendre et utiliser les "Capabilities"
Les "capabilities" permettent de diviser les droits de l'utilisateur root en plusieurs droits spécifiques, offrant ainsi une granularité accrue. Par défaut, les containers héritent de toutes les "capabilities", mais il est essentiel de les restreindre via le runtime (Docker, Podman, Kubernetes). Voici quelques exemples de "capabilities":
- setuid : Changer d'identité.
- net_raw : Accéder aux trames réseau.
- chown : Changer les droits d'un fichier.
- setcap : Changer les "capabilities".
La plupart des applications cloud-native n'ont pas besoin de ces droits étendus. Il est donc recommandé de restreindre les "capabilities" pour réduire la surface d'attaque.
Utiliser des "Golden Images"
Les "Golden Images" sont des images sources connues et réputées, récupérées sur des registres officiels. Utiliser ces images comme base pour construire vos containers garantit un niveau de sécurité et de fiabilité élevé. Les images construites doivent contenir le minimum nécessaire pour fonctionner. Par exemple, il est préférable de construire l'image via un Dockerfile en double stage : l'application est d'abord construite dans une image contenant tous les outils nécessaires (BUILDER), puis le résultat est extrait et copié dans une image destination très légère et minimale (comme les images distroless de Google).
Monter le Filesystem en lecture seule
Monter le filesystem du container en lecture seule, ainsi que tous les volumes qui n'ont pas besoin d'être modifiés, permet de limiter les risques de modification ou de compromission. Si un espace d'écriture est nécessaire, il est recommandé d'utiliser un point de montage de type ramdisk.
Ne Pas Stocker de Secrets dans le Container
Aucun secret ne doit être stocké dans le container, y compris dans les métadatas et les layers. Effacer un secret au cours des instructions du Dockerfile donne l'impression que le secret a disparu, mais il reste présent dans un layer. Utilisez des outils comme dive pour inspecter l'image et vérifier l'absence de secrets.
Imposer des règles via Gatekeeper
Dans Kubernetes, l'outil Gatekeeper permet de pousser des politiques de sécurité, comme l'interdiction des containers en root ou avec trop de "capabilities". Cela force les équipes de développement à respecter les règles de sécurité définies.
Debugger en production avec des containers éphémères
Pour ceux qui craignent de ne pas pouvoir debugger en production avec une image minimale et sans shell, il est possible de profiter des possibilités de partage des namespaces (PID, réseau, volume) entre containers. Utilisez un container éphémère qui partage ses namespaces pour accéder au filesystem ou aux ports réseau de l'application.
Process management : Build, deploy, scan
Patcher un container n'est pas la méthode recommandée pour la gestion des processus. Bien que cela soit possible, il est préférable de suivre une approche de build, deploy et scan fréquents pour assurer une maintenance régulière. Des outils comme Copacetic de Microsoft peuvent être utilisés ponctuellement pour assurer un minimum de sécurité sur des containers non maintenus.
Sécuriser le réseau Kubernetes
Par défaut, le réseau de Kubernetes est flat et sans isolation, permettant à tous les pods de communiquer entre eux. Il est crucial d'implémenter des NetworkPolicies en Ingress et Egress pour sécuriser ce réseau et limiter les communications non autorisées.
J’ai perdu du poids sur Kubernetes avec Slimfaas
L'équipe d'AXA a présenté un projet innovant visant à optimiser l'utilisation des ressources cloud grâce à SlimFaas, une solution légère et efficace pour gérer les charges de travail. Ce projet est né de la nécessité de réduire les coûts liés au traitement de documents administratifs (comme les cartes d'identité) à l'aide de processus d'intelligence artificielle.
Contexte : réduire les coûts tout en maintenant l'efficacité
Pour traiter ces documents, AXA utilisait des instances GPU coûteuses, principalement lorsqu'elles étaient actives. L'objectif était de ne les utiliser que pendant les périodes de traitement, en adoptant une approche containerisée, tout en permettant un "downscale" à zéro lorsque les instances n'étaient pas nécessaires. Le processus métier, découpé en étapes synchrones et asynchrones, nécessitait un déclenchement (trigger) fluide entre les différentes étapes.
La naissance de SlimFaas
Plusieurs solutions open source comme Knative, OpenFaaS et KEDA ont été testées, mais elles se sont révélées trop complexes à maintenir dans ce contexte. C'est ainsi que SlimFaas a vu le jour. SlimFaas est un simple reverse proxy déployé comme un pod ou un déploiement (avec 3 réplicas recommandés), offrant une solution non intrusive et facile à maintenir sur un cluster Kubernetes.
Un système de file d'attente (queuing) est intégré pour gérer les processus asynchrones, tandis que le protocole Raft est utilisé pour l'élection d'un maître (master). De plus, une base de données est incluse pour assurer la persistance entre les pods.
Simplicité et efficacité : un potentiel game-changer
SlimFaas se distingue par sa légèreté et sa facilité d'implémentation. Une simple annotation sur les pods "worker" permet à SlimFaas de les gérer efficacement. Un système de "wake-up" (réveil) permet de démarrer un pod en avance lorsqu'un processus nécessite un temps de démarrage prolongé (warmup).
Une API a également été ajoutée pour lister l'état des pods gérés par SlimFaas, facilitant ainsi la gestion et le suivi des ressources.
La présentation a été ponctuée de démonstrations en direct, directement à partir du dépôt GitHub du projet, permettant aux participants de suivre chaque étape du processus. AXA invite d'ailleurs la communauté à explorer et à utiliser SlimFaas, disponible sur leur dépôt GitHub : https://github.com/AxaFrance/SlimFaas.
En prime, SlimFaas est présenté comme une solution "green", susceptible de contribuer à la réduction de l'empreinte carbone, ou comme l'a formulé l'équipe, "ça peut sauver des pingouins !"
Hacking code : exploiter le code généré par l’IA
Lors de la conférence, les limites des IA ont été abordées, notamment leur tendance à affirmer des résultats incorrects avec confiance et à produire des "hallucinations". Des exemples simples, comme l'addition de deux entiers, ont montré que les IA peuvent se tromper et se contredire.
La démonstration s'est ensuite concentrée sur Co-pilot, utilisé pour enrichir une application de gestion de planning. Bien que l'IA fournisse des solutions rapides et fonctionnelles, des failles exploitables sont vite apparues, révélant ses limites.
L'IA est un puissant accélérateur, mais les développeurs doivent garder un esprit critique. Intégrer des outils de scan de code dans l'IDE, comme SAST et DAST, renforce la sécurité des suggestions fournies par l'IA.

🌍 Mesure ton empreinte avec Cloud Carbon Footprint 👣
Lors de cette conférence, l'impact environnemental du cloud a été mis en lumière, avec un accent sur l'empreinte carbone des data centers. Zatsit, acteur dans ce domaine, a introduit la session en exposant l'existence d'outils de mesure telle que ceux que l'on peut trouver dans le top 10 publié par Github
Parmi eux, "Cloud Carbon Footprint" a été présenté comme un outil clé pour mesurer l'empreinte carbone des services cloud à partir des données de facturation.
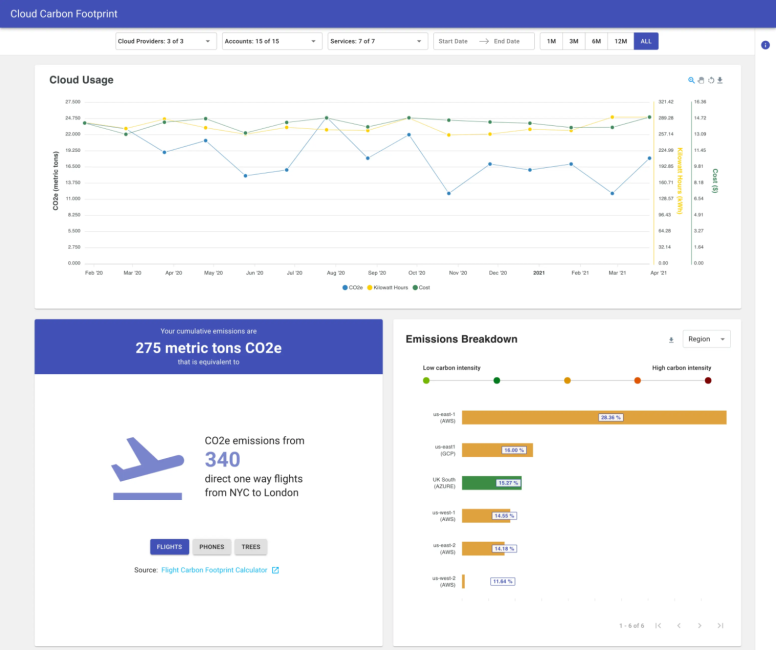
L'exemple d'Etsy a été cité, qui a pris des mesures concrètes pour réduire ses émissions, a illustré l’importance d’une approche proactive.
Emmanuel de Zatsit, nous a également fait une démonstration de l'outil et de sa simplicité d'installation et d'utilisation.
Par ailleurs, pour davantage de précision, le calcul de l'empreinte carbone repose sur des outils comme Electricity Maps pour affiner les résultats en fonction de la source d’énergie utilisée.
Conclusion
Lors de notre journée à Cloud Nord, nous avons eu l'opportunité de plonger plus profondément dans différentes thématiques.
Les discussions et ateliers ont permis de mettre en lumière l'importance de sécuriser chaque étape du cycle de vie des containers. Les experts présents ont partagé des insights précieux et des retours d'expérience concrets, renforçant l'idée que la sécurité est un effort collectif et continu. Cette journée a été une véritable source d'inspiration et de connaissances, nous rappelant que dans le monde du cloud et des containers, la vigilance et l'innovation sont nos meilleurs alliés.

 Jérôme DevoucouxSeifeddin Mansri
Jérôme DevoucouxSeifeddin Mansri Philippe JOURDAN
Philippe JOURDAN Romain Chabaud
Romain Chabaud![[KubeCon 25] Comment sécuriser vos conteneurs Kubernetes avec Falco et Talon ?](/content/images/size/w1304/2025/04/falco2.png)




{kind=link}