
Introduction
Déplacer certaines de nos charges de travail dans le cloud est maintenant chose courante pour beaucoup d'entreprises. Cependant, avant de lancer nos premiers conteneurs ou nos premières fonctions as a service, il faut créer nos fondations. Sous Google Cloud, cela se traduit de manière non exhaustive par la mise en place des org policies, de la facturation, des rôles personnalisés, du Workload Identity Federation ou encore par l'interconnexion entre un éventuel réseau on-premise et Google cloud. Avec un ensemble de blueprints et de modules basés sur Terraform, Google propose au travers de sa fabric un outil permettant de créer des landing zones utilisables en production.
La fast fabric
Afin de faciliter la mise en place d'une landing zone, l'outil de Google propose aussi Fast, un ensemble de fichiers Terraform rassemblés en stages, à lancer dans un ordre précis et utilisant les outputs pour assurer la cohérence entre les stages. Ils s'appuient sur des modules maintenus par Google et nous permettent de créer nos fondations étape par étape. Pour commencer à jouer avec, il suffit de cloner le dépôt suivant :
git clone https://github.com/GoogleCloudPlatform/cloud-foundation-fabric.gitLes stages
Ils ne sont pas tous nécessaires au déploiement d'une landing zone. Les principaux à utiliser sont les suivants:
0-bootstrap
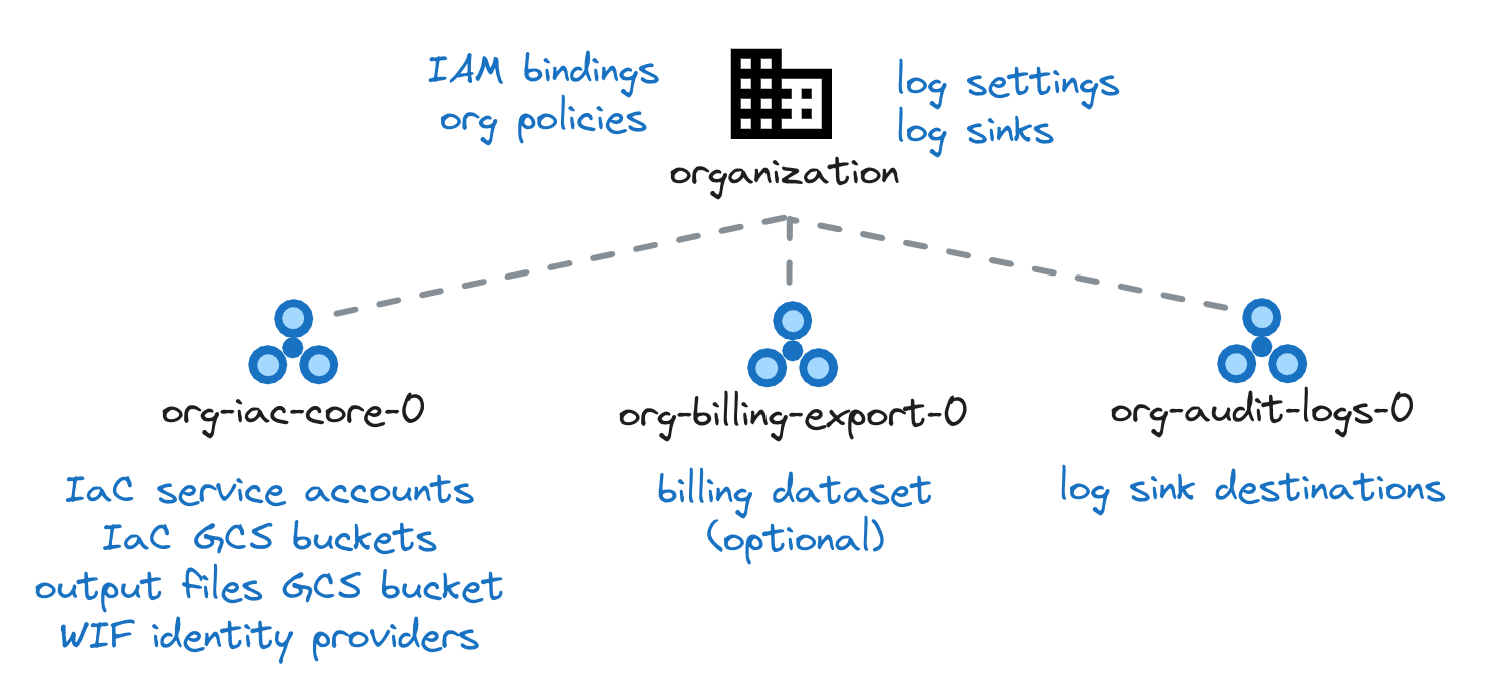
Ce stage permet de mettre en place les éléments suivants (liste non exhaustive)
- Org policies: Des exemples sont fournis dans le projet, mais cela permet à une organisation de restreindre la création de ressources à une région spécifique. De plus, elle peut limiter les types de VM utilisables ou interdire les adresses IP externes sur celles-ci, par exemple.
- Projets de démarrage: Mise en place d'un projet dédié à la facturation, aux audits logs et à l'automatisation.
- Workload Identity & Automatisation: Création de buckets pour stocker les states terraform, les fichiers providers et les fichiers de variables des différents stages. En utilisant les variables
cicd_repositoriesetworkload_identity_providers, le WIF sera configuré pour permettre aux pipelines de se connecter à Google Cloud sans avoir besoin de comptes de service. - Comptes de services: Création des comptes de services pour l'automatisation au travers de l'impersonate (prendre le rôle d'un compte de service ayant des droits supérieurs aux nôtres).
- Attribution de droits aux groupes: attributions de droits aux groupes
gcp-devopsgcp-billing-adminsgcp-network-adminsgcp-organization-adminsgcp-security-admins, afin de permettre aux personnes de l'organisation de travailler convenablement, tout en respectant la règle du moindre privilège. Attention, ces groupes sont malgré tout permissifs, car destinés à des personnes de type administrateur.
En suivant la documentation, il est nécessaire de lancer plusieurs commandes pour créer les comptes de service dont on utilisera les droits par la suite. Il faut également lier le compte de facturation de l'organisation et créer les buckets qui seront utilisés pour stocker les états Terraform.
On commence par se placer dans le dossier 0-bootstrap
cd fast/stages/0-bootstrapAttribuer les droits au compte d'initialisation :
# set variable for current logged in user
export FAST_BU=$(gcloud config list --format 'value(core.account)')
# find and set your org id
gcloud organizations list
export FAST_ORG_ID=123456
# set needed roles
export FAST_ROLES="roles/billing.admin roles/logging.admin \
roles/iam.organizationRoleAdmin roles/resourcemanager.projectCreator \
roles/resourcemanager.organizationAdmin roles/resourcemanager.tagAdmin \
roles/owner"
for role in $FAST_ROLES; do
gcloud organizations add-iam-policy-binding $FAST_ORG_ID \
--member user:$FAST_BU --role $role --condition None
doneUne fois les droits en place sur le compte, peupler le fichier terraform.tfvars, afin de fournir les informations relatives à notre organisation. En voici un exemple :
billing_account = {
id = "H3XA01-H3XA02-H3XA03" #Billing id de l'organisation
}
# Region de GCS, BigQuery et des logs buckets.
locations = {
bq = "EU"
gcs = "EU"
logging = "eu"
pubsub = []
}
# utiliser `gcloud organizations list` pour trouver les informations.
organization = {
domain = "domaine.com"
id = 1111111092111
customer_id = "CUST0MERID"
}
prefix = "dom" # prefix appliqué à toutes les ressources
groups = {
gcp-devops = "dom-gcp-devops"
gcp-billing-admins = "dom-gcp-bil-admin"
gcp-network-admins = "dom-gcp-net-admin"
gcp-organization-admins = "dom-gcp-org-admin"
gcp-security-admins = "dom-gcp-secu-admin"
}
# exemple d'ajout de droits pour des personnes ou des groupes
iam_bindings_additive = {
# "user:prenom.nom@domain.com" = [
# { role = "roles/logging.admin" },
# ]
# "group:dom-gcp-log-admin@domain.com" = [
# { role = "roles/logging.admin" },
# { role = "roles/resourcemanager.folderAdmin" },
# ]
}
log_sinks = {
audit-logs = {
filter = "logName:\"/logs/cloudaudit.googleapis.com%2Factivity\" OR logName:\"/logs/cloudaudit.googleapis.com%2Fsystem_event\""
type = "logging"
}
}
workload_identity_providers = {
# Use a private instance of Gitlab and specify a custom issuer_uri
gitlab = {
issuer = "gitlab"
name = "gitlab-wif"
custom_settings = {
issuer_uri = "https://gitlab.domain.com"
audiences = ["https://gitlab.domain.com"]
jwks_json = "<mon_jwks>"
}
}
}
cicd_repositories = {
bootstrap = {
name = "bootstrap"
type = "gitlab"
branch = "main"
identity_provider = "gitlab"
}
resman = {
name = "resman"
type = "gitlab"
branch = "main"
identity_provider = "gitlab"
}
}Maintenant, lancer un terraform apply en utilisant la variable bootstrap_user permettant de créer l'essentiel au lancement du second apply.
terraform init
terraform apply \
-var bootstrap_user=$(gcloud config list --format 'value(core.account)')Il faut maintenant récupérer le provider généré actuellement stocké dans un bucket, afin de migrer le state Terraform dans Google Cloud et finir le bootstrap. La partie suivante sera la gestion des ressources. Utiliser la commande ci-dessous en remplaçant dom par le préfixe choisi précédemment :
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/providers/0-bootstrap-providers.tf ./Appliquer une nouvelle fois le terraform, sans variable, afin de créer l'ensemble des ressources, en pensant à migrer les states dans le bucket dédié à cet effet :
terraform init --migrate-state
terraform apply1-resman
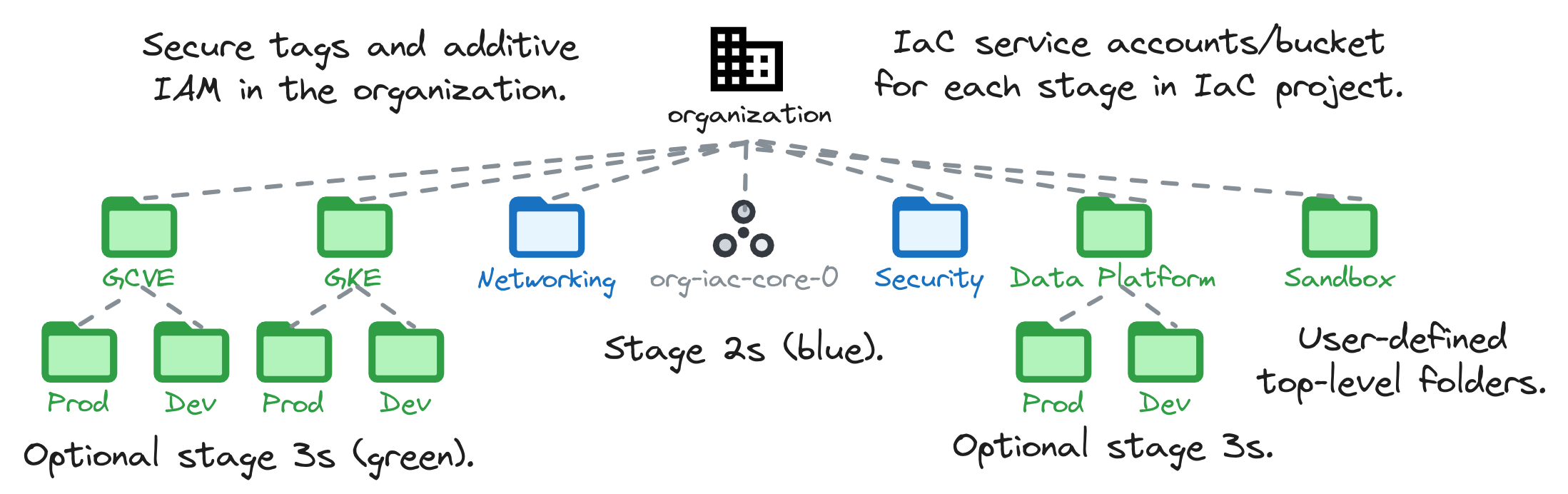
Ce stage permet de créer les dossiers Networking et Security afin de centraliser les projets, de mettre en place la CI/CD pour les stages networking, project factory, ..., de déployer une sandbox, des arborescences "typiques" (data, gke, etc.) ou bien des dossiers de premier niveau.
Pour lancer ce stage, il faut commencer par récupérer les variables du stage bootstrap et le provider généré, actuellement dans le bucket du projet iac-core-0. Pour cela, on lance les commandes cloud suivantes (penser à changer le préfixe) :
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/providers/1-resman-providers.tf ./
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/tfvars/0-globals.auto.tfvars.json ./
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/tfvars/0-bootstrap.auto.tfvars.json ./On vient mettre à jour notre terraform.tfvars pour créer le dossier racine data, activer la project_factory, et mettre en place le workload identity federation pour les projets networkinget project_factory
# Lister dans top_level_folders la liste des folders à créer au premier niveau
top_level_folders = {
data = {
name = "data"
parent = "folders/nnnnnnnnnn" #A remplacer par l'id du dossier
automation = {
enable = false
}
# iam = {
# "roles/viewer" = [
# "group:test-1-viewers@domaine.com"
# ]
#}
}
}
fast_features = {
project_factory = true
}
cicd_repositories = {
networking = {
name = "networking"
type = "gitlab"
branch = "main"
identity_provider = "gitlab"
}
project_factory_dev = {
name = "project_factory_dev"
type = "gitlab"
branch = "main"
identity_provider = "gitlab"
}
project_factory_prod = {
name = "project_factory_prod"
type = "gitlab"
branch = "main"
identity_provider = "gitlab"
}
}On peut maintenant créer l'arborescence avec les commandes init, plan et apply de terraform :
terraform init
terraform plan
terraform apply2-networking
Cette partie est divisée en plusieurs stages possibles, mais seul le 2-networking-a-simple sera présenté ici. Il permet de mettre en place un VPN HA entre l'on-premise d'une entreprise et Google Cloud afin de se connecter à des bases de données, envoyer les logs ou récupérer des fichiers. L'architecture mise en place est de type hub & spoke, tous les flux passant par la zone landing comme le montre le schéma suivant :

Récupérer dans un premier temps les fichiers nécessaires à l'exécution de ce stage :
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/providers/2-networking-providers.tf ./
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/tfvars/0-globals.auto.tfvars.json ./
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/tfvars/0-bootstrap.auto.tfvars.json ./
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/tfvars/1-resman.auto.tfvars.json ./Comme dans les précédentes étapes, il faut remplir le fichier terraform.tfvars dans le but de configurer le VPN.
vpn_onprem_primary_config = {
peer_external_gateways = {
default = {
redundancy_type = "SINGLE_IP_INTERNALLY_REDUNDANT"
interfaces = ["8.8.8.8"]
}
}
router_config = {
asn = 65501
custom_advertise = {
all_subnets = false
ip_ranges = {
"10.1.0.0/16" = "gcp"
"35.199.192.0/19" = "gcp-dns"
"199.36.153.4/30" = "gcp-restricted"
}
}
}
tunnels = {
"0" = {
bgp_peer = {
address = "169.254.1.1"
asn = 65500
}
bgp_session_range = "169.254.1.2/30"
peer_external_gateway_interface = 0
shared_secret = "foo"
vpn_gateway_interface = 0
}
"1" = {
bgp_peer = {
address = "169.254.2.1"
asn = 64513
}
bgp_session_range = "169.254.2.2/30"
peer_external_gateway_interface = 1
shared_secret = "foo"
vpn_gateway_interface = 1
}
}
}On peut y rajouter la création de VMs de test dans les VPC spokes, la mise en place du cloud NAT afin d'avoir une sortie internet sur nos VMs, les IPs de nos resolvers DNS ou encore privilégier un VPN entre le hub et les spokes, afin de garder la transitivité (le VPC A peut parler au VPC C au travers du VPC B), sans avoir à définir de règles de routage. Pour cela, ajouter les variables suivantes dans le fichier terraform.tfvars :
# Permet la création d'un tunnel entre hub et spoke
spoke_configs = { vpn_configs = {} }
# Permet de mettre en place de DNS forwarding
dns = {
resolvers = ["192.168.1.1","192.168.1.2"]
enable_logging = true
}
# Créer des vms spot de test dans les VPC spoke et le hub
create_test_instances = false
# Permet d'obtenir internet sur les VMs qui n'ont pas d'ip externe
enable_cloud_nat = falseSi le terraform est appliqué, les subnets pour le hub et les spokes seront ceux définis dans les fichiers data/subnets/dev , data/subnets/landing et data/subnets/prod. Ne pas oublier de les adapter si nécessaire.
De plus, si des règles de firewall sont à définir directement dans les Shared VPC, il est possible d'utiliser les fichiers data/firewall-rules/dev/rules.yaml, data/firewall-rules/landing/rules.yaml et data/firewall-rules/prod/rules.yaml
Appliquer le terraform comme précédemment :
terraform init
terraform plan
terraform applyNotre landing zone est maintenant en place. Les comptes de service sont créés, les dossiers et le réseau fonctionnel. Il reste une partie intéressante de la fast fabric, nommée project factory.
3-project-factory
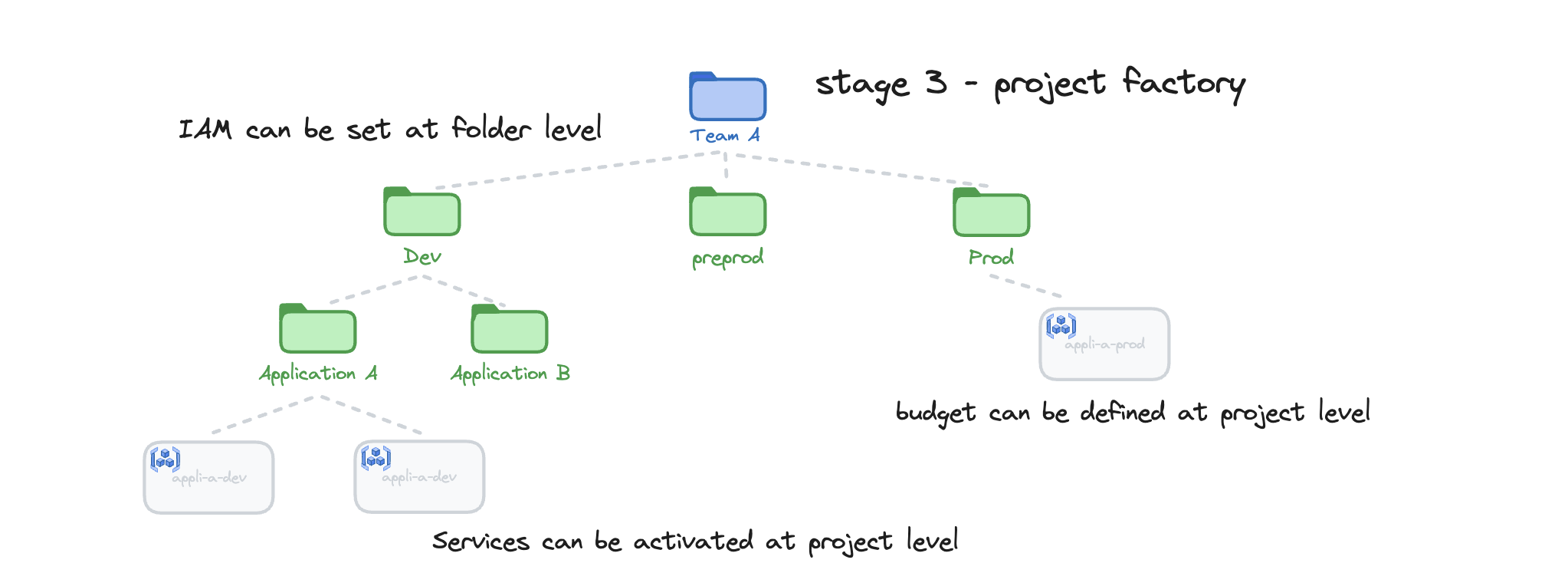
Cette étape a pour but de créer l'arborescence des dossiers contenant les projets et de créer des projets avec l'automatisation et des paramètres prédéfinis, réduisant le risque d'erreur, tout en ayant l'ensemble as code. Comme chaque début de stage, on récupère les fichiers nécessaires
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/providers/3-project-factory-providers.tf ./
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/tfvars/0-globals.auto.tfvars.json ./
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/tfvars/0-bootstrap.auto.tfvars.json ./
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/tfvars/1-resman.auto.tfvars.json ./
gcloud alpha storage cp gs://dom-prod-iac-core-outputs-0/tfvars/2-networking.auto.tfvars.json ./Ce stage comporte seulement une variable factories_config à instancier dans le fichier terraform.tfvars, permettant de définir le chemin où se trouve les fichiers yaml. Un exemple est :
factories_config = {
hierarchy = {
folders_data_path = "data/hierarchy"
parent_ids = {
default = "folders/1234567890"
}
}
projects_data_path = "data/projects"
}
Pour créer l'arborescence Dev/Application A/application-a-dev, il faut donc créer le fichier application-a-dev.yaml dans le dossier data/hierarachy/Dev/Application A/.
services:
- compute.googleapis.com
- storage.googleapis.com
- datastream.googleapis.com
- bigquery.googleapis.com
shared_vpc_service_config:
host_project: dom-dev-net-spoke-0
labels:
contact_primary: admin-domaine
environment: dev
workload: bigquery
iam:
roles/compute.admin:
- group:dom-grp-dev-admin@domaine.com
roles/owner:
- group:dom-grp-dev-appa-owner@domaine.comChaque dossier peut avoir ses propres droits IAM, en les définissant dans un fichier _config.yaml. Voici comment ajouter les droits en lecture au groupe dom-grp-dev-reader au dossier dev au travers de la création du fichier data/hierarchy/dev/_config.yaml
name: Dev
iam:
roles/viewer:
- group:dom-grp-dev-reader@domaine.comOn peut maintenant appliquer notre terraform afin de créer les dossiers et le projet.
terraform init
terraform plan
terraform applyConclusion
Il est facile de le coupler avec des outils tels que Gitlab-CI ou encore GitHub Action afin d'automatiser la création de nos ressources. Ceci pourra faire l'objet d'un autre article.
En résumé, cet outil est un ensemble de module Terraform permettant de créer une landing zone de zéro et en respectant les bonnes pratiques de Google. Bien sur, cette rapidité se troque contre la modularité. Beaucoup de paramètres sont à modifier dans les fichiers .tf si ceux par défaut ne conviennent pas aux besoins. Dans ce cas, il faudra prendre en main l'outil, ce qui est forcément plus compliqué qu'avec des modules que l'ont a développé, mais le jeu en vaut la chandelle 😄.



![[03] Streamlining Data Understanding avec Gemini CLI](/content/images/size/w1304/2025/09/Gemini_CLI_Streamlining_Data_Understanding.png)



{kind=link}