
Il y a environ un an, je suis tombé sur une vidéo de Benjamin Code à propos d'un Data Scientist qui utilisait un compte Instagram afin de manger gratuitement à New York.
Je commençais également mon parcours sur Google Cloud Console et je déménageais à Paris pour rejoindre SFEIR. Cette vidéo m’a fait penser qu’il y avait là une opportunité pour profiter de nourriture gratuite et acquérir de l'expérience avec Google Cloud Platform. J'ai donc décidé de créer un bot Instagram.

Ma stratégie
Obtention du contenu:
J'ai ré-implémenté la même stratégie que dans la vidéo.
Tout d'abord, trouver quelques comptes sur Paris et récupérer leurs photos.
Ensuite, filtrer sur la localisation mais aussi sur la description. Parfois, ils pouvaient avoir un contenu promotionnel ou plus personnel que je ne voulais pas relayer.
Puis, j'ai extrait les 30 tags les plus utilisés dans leurs photos parisiennes.
J'ai également généré une google sheet contenant 100 citations sur Paris que j'utiliserai au hasard comme descriptions.
Enfin, j'ai extrait les followers de ces comptes et leur ai envoyé des demandes de follow avant de les unfollow deux jours plus tard, afin de développer mon audience en ciblant des personnes intéressées par le type de contenu que je proposais.
Les images ont été stockées dans un bucket cloud storage et le reste des données dans google sheet ou big query.
Publication
Chaque matin, une image était sélectionnée au hasard dans le bucket cloud storage, puis une citation au hasard était choisie parmi les citations du google sheet, en ajoutant les 30 tags, en citant le propriétaire de l'image (sinon cela serait injuste envers leur travail) et en publiant sur le compte.
Développer l'audience
Avoir un contenu de qualité est une chose, mais s'il n'y a personne pour le voir, autant crier dans le vide. J'ai donc fait quelques bricolages et après quelques essais et erreurs et avoir été bloqué par Instagram plusieurs fois, j’ai peaufiné mon bot de la manière suivante:
Envoyer des demandes de follow et unfollow à différents moments de la journée et follow/unfollow environ 150 personnes (donc 75 suivi et 75 dé-suivi) par jour ce qui semble être le maximum avant qu’Instagram ne trouve ce comportement suspect.
Le follow et le unfollow deux jours plus tard peuvent sembler impolis, mais c'est ce que vous devez faire pour maintenir une audience avec un bon niveau d'engagement et un bon ratio follower/followed.
De plus, tant qu'ils reçoivent de la qualité et qu'ils apprécient le contenu, je pense que c'est une situation gagnant-gagnant.
Ma Stack
Le principal objectif était d'acquérir de l'expérience avec Google Cloud dans un projet amusant en exploitant les 300 euros et 3 mois de services gratuits offerts par Google. Cela m'a donné l'opportunité de me faire la main avec les Cloud function, Big Query et le Cloud storage

BigQuery est un data warehouse entièrement managé, server less et basé sur le cloud qui permet des requêtes évolutives similaires à SQL sur des ensembles de données massifs. Il permet aux utilisateurs d'interroger rapidement et facilement des ensembles de données volumineux et complexes à l'aide de requêtes similaires à SQL et en s'intégrant à d'autres produits Google Cloud pour la visualisation et l'apprentissage automatique. Avec BigQuery, les utilisateurs peuvent accéder aux données stockées dans différents formats, y compris CSV, JSON et Avro, et les interroger à l'aide d'une syntaxe familière similaire à SQL. BigQuery est hautement évolutif et peut traiter des téraoctets de données en quelques secondes, ce qui en fait un outil puissant pour l'analyse de données et l'intelligence d'affaires.
J'ai d'abord pensé à utiliser Cloud SQL car il était plus adapté aux besoins transactionnels de cette application. Cependant, il était beaucoup plus cher que l'utilisation de BigQuery, j'ai donc fait ce choix.

Cloud Storage est un service de stockage d'objets basé offert par Google. Il permet aux utilisateurs de stocker et d'accéder aux données sur l'infrastructure de Google, offrant ainsi un stockage fiable et sécurisé pour une grande variété de types de données. Google Cloud Storage propose plusieurs classes de stockage différentes, notamment Nearline, Coldline et Archive, qui répondent aux différents besoins de stockage de données et budgets. Il offre également une intégration avec d'autres produits Google Cloud, tels que Google BigQuery pour l'analyse de données et Google Compute Engine. Avec Google Cloud Storage, les utilisateurs peuvent stocker, gérer et accéder à leurs données depuis n'importe où dans le monde, ce qui en fait un outil puissant pour le stockage et la gestion des données.
J'ai d'abord utilisé Google Cloud Storage pour télécharger les données CSV que j'ai ensuite chargées dans BigQuery, ainsi que les photos qui ont été extraites d’Instagram.

Les Cloud Functions sont une plateforme de calcul server less et événementielle offerte par Google Cloud. Elle permet aux utilisateurs d'écrire et de déployer de petites fonctions à usage unique qui répondent à des événements et s'exécutent automatiquement et s'adaptent à l'échelle, sans avoir besoin de gérer l'infrastructure. Google Cloud Functions fournit un moyen hautement évolutif et rentable de construire et de déployer des applications et des microservices sans serveur. Elle s'intègre parfaitement avec d'autres produits Google Cloud et prend en charge plusieurs langages de programmation, y compris Node.js, Python et Go. Avec Google Cloud Functions, les développeurs peuvent se concentrer sur l'écriture de code plutôt que de s'inquiéter de l'infrastructure, ce qui en fait un outil puissant pour la construction d'applications modernes, nativement dans le cloud. C'est une bonne façon d'exécuter du code sur demande de manière peu coûteuse et efficace.

J'ai d'abord pensé à utiliser Compute Engine, un service de machine virtuelle basé sur le cloud proposé par Google Cloud. Il permet aux utilisateurs de gérer des machines virtuelles, ou des instances de calcul, sur l'infrastructure de Google, offrant des ressources informatiques évolutives et haute performance. Avec Compute Engine, les utilisateurs peuvent créer et configurer des machines virtuelles avec une variété de systèmes d'exploitation, de processeurs et d'options de mémoire, et y accéder via Internet. Compute Engine offre également une gamme d'autres fonctionnalités, telles que l'équilibrage de charge et l'intégration avec d'autres produits Google Cloud, ce qui en fait un outil puissant et flexible pour exécuter une grande variété de charges de travail informatiques.
Cependant, il était à la fois coûteux et pas assez flexible à mon goût, surtout étant donné que j'aurais besoin d'utiliser Selenium et certaines manipulations d'interfaces graphiques qui n'étaient pas bon marché dans GCP.
En conséquence, j'ai choisi de travailler localement en utilisant Python et Selenium pour le scrapping.
L’Histoire
La première étape a été de scraper les données de 10 comptes Instagram proposant des photos de Paris. J’ai scrapé la localisation, le nom du profil, la description et les tags employés.
J'ai également scrapé leurs abonnés. Je les ciblerai plus tard en leur envoyant des demandes de follow. Mais avoir scrapé leurs photos ne suffit pas. Ces comptes sont des comptes personnels, il se peut donc que certaines des photos ne soient pas à Paris ou soient des contenus sponsorisés que je ne veux pas relayer. Donc, j'ai d'abord ajouté un filtre sur la localisation et filtré tout ce qui n'était pas situé à Paris et autour de Paris. Ensuite, en utilisant un peu de regex, j'ai supprimé le contenu basé sur les descriptions s'ils n'étaient pas orientés "paysages de Paris". Enfin, pour être sûr de ne pas avoir de doublons dans mes images, car peut-être que certains de ces comptes relayaient en fait des images tout comme moi. J'ai créé des hashs des images et les ai utilisés pour dé-dupliquer les images. Ainsi, j’ai obtenu un répertoire d'images uniques et de haute qualité que je pouvais utiliser.

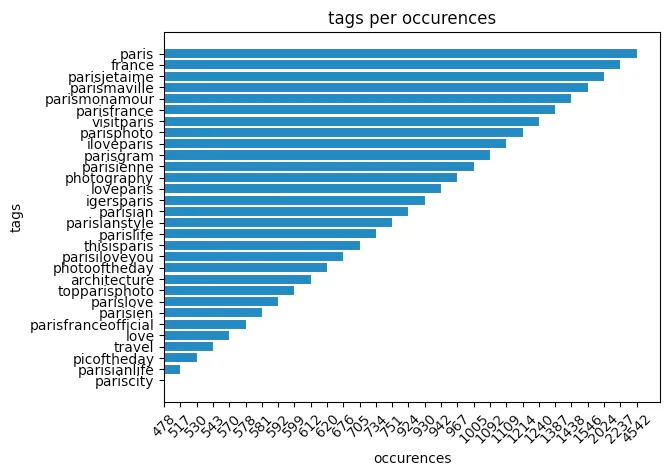
L'étape suivante consistait à optimiser les tags. J'ai opté pour une méthode simple en cherchant les tags dans les descriptions. J'ai compté chacun d'entre eux et sélectionné les 30 plus courants comme tags. Pour Paris, voici les tags sélectionnés.
Finalement, j'ai créé une liste de 100 citations sur Paris dans une feuille de calcul Google provenant de différents acteurs, auteurs, artistes... Tout comme j'ai chargé les données pour les images, je les ai chargées dans BigQuery.

J'étais maintenant prêt à créer une audience. J'avais le contenu et j'avais les cibles. J'ai choisi de poster une fois par jour, d'abord manuellement, en utilisant des interfaces en ligne de commande appelant mes scripts et en faisant des essais et erreurs pour déterminer le nombre optimal de follow/unfollow par jour afin de ne pas être bloqué par Instagram
Poster une image et une citation
Follow et unfollow
Ensuite, j'ai automatisé tout le processus en utilisant Python et quelques tâches cron. Les photos, une fois publiées, voient leur statut dans la table "insta_paris_table" passer de faux à vrai pour éviter les doubles publications (BigQuery n'est pas optimisé pour les mises à jour, mais avec cette quantité limitée par jour, ce n'était pas un problème). Les comptes suivis seraient ajoutés de la table "raw_followers_table" à "followed_accounts". Chaque jour, en fonction de la date de suivi, le script se désabonne des personnes qui ont été suivies deux jours auparavant.
Tout fonctionnait très bien pendant un certain temps et la croissance était constante. À un moment donné, une partie de l'automatisation a été interrompue en raison de certains changements dans l'interface Instagram, puis est revenue en état opérationnel. Cependant, maintenant, de nombreuses fonctionnalités ne fonctionnent plus car Instagram a considérablement changé son interface et je n'ai pas pris le temps de faire des modifications en conséquence. Cela étant dit, cela fonctionne encore suffisamment bien pour gagner beaucoup de temps et augmenter l'audience.
ROI
Voici quelques données fournies par l'application Instagram pour les entreprises (des données que vous pouvez obtenir une fois éligible à la monétisation, ce qui fait donc officiellement de moi un influenceur). Comme elles ne couvrent pas toute la durée de vie du compte, les données peuvent ne pas être entièrement représentatives, mais elles sont une bonne estimation de la démographie de mon public.
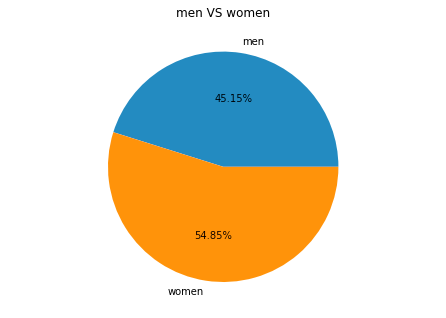
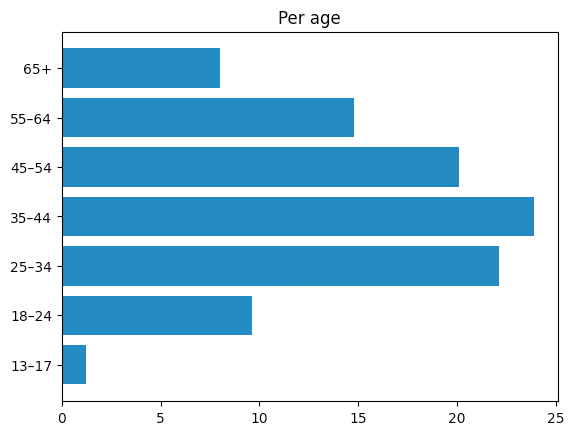
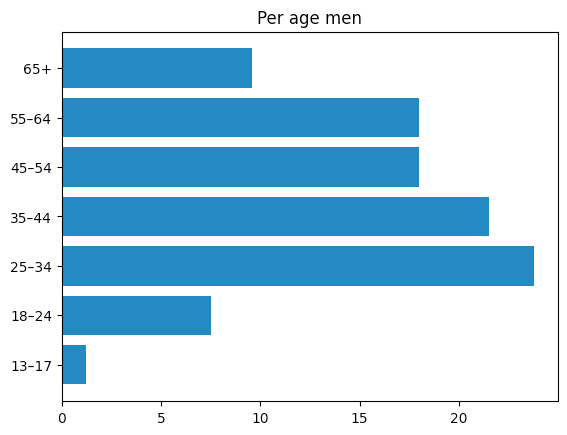
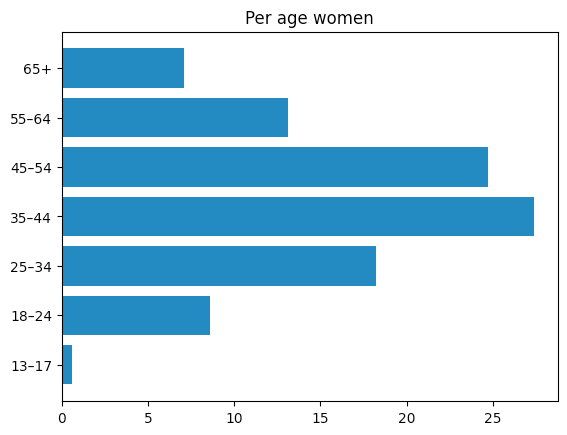
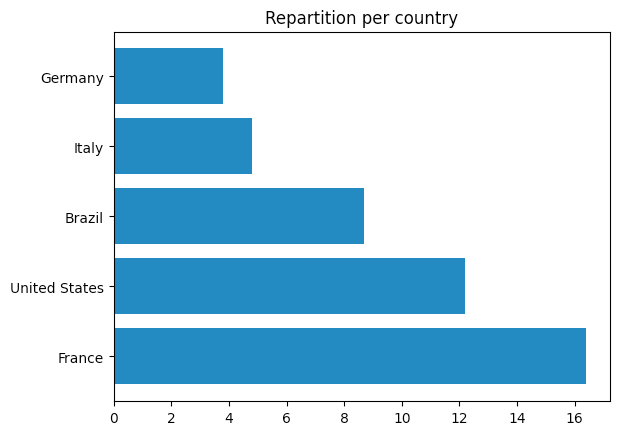
La plupart de mon audience semble en fait être composée de personnes de France et des États-Unis. Il semble également qu'il y ait une légère préférence pour les femmes entre 35 et 55 ans.
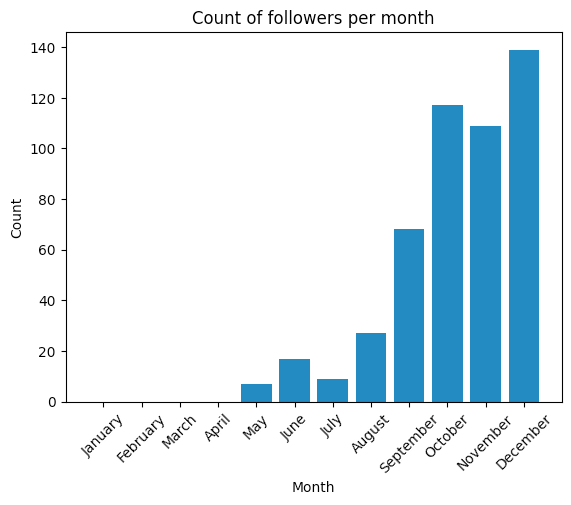
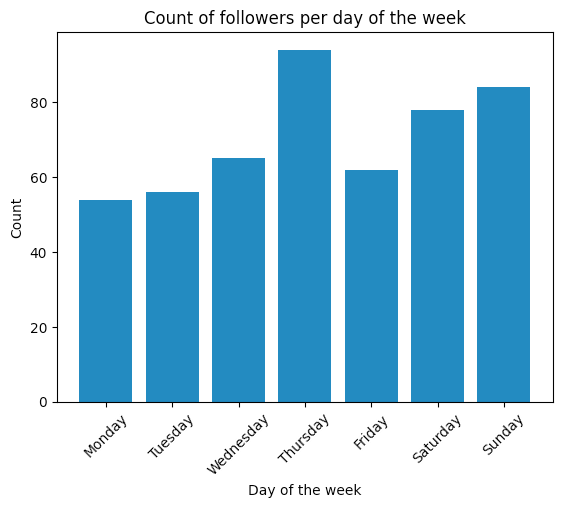
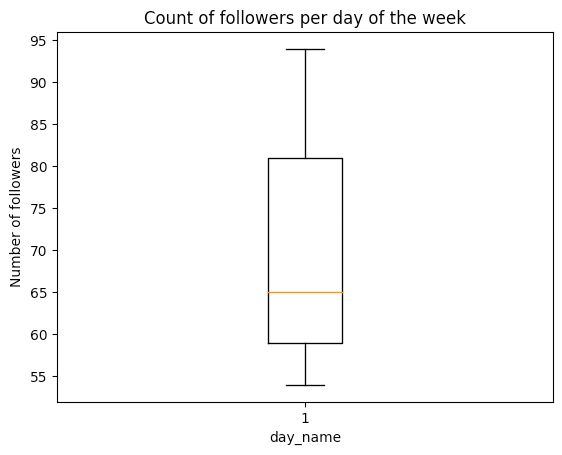
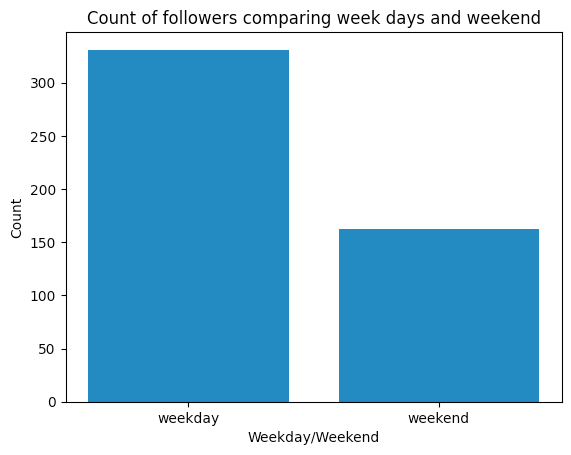
Décembre était un très bon mois, peut-être parce que le compte commençait à avoir de la traction, je me souviens que certains des nouveaux abonnés commençaient à être des abonnés "organiques". De plus, il semble que le jeudi, le samedi et le dimanche soient les meilleurs jours pour mon public cible.
Prochaines étapes
J'utilise encore le bot pour publier même si les dernières mises à jour de l'interface d'Instagram ont rendu certains de mes scripts d'automatisation redondants.
Par exemple, la publication de photos ne fonctionne plus et le processus de follow/unfollow n'est plus aussi efficace qu'auparavant. Cela fonctionne toujours, mais il arrive parfois qu'il suive à nouveau des personnes que j'ai désabonnées. J'ai pris un peu de temps pour corriger ces bugs, mais je n'ai pas encore trouvé de solution entièrement fonctionnelle. Cela étant dit l'audience continue de croître même si ce n'est pas aussi efficace qu'avant. Cela m'a également permis d'obtenir un compte professionnel sur Instagram, ce qui fait de moi un influenceur à part entière, mission accomplie.





![[04] Data Engineering avec Gemini CLI](/content/images/size/w1304/2025/10/Gemini_CLI_Data_Engineering.png)



{kind=link}