
Dans le monde du traitement du langage naturel (NLP), mesurer la similarité entre des corpus de texte est une tâche fondamentale. Que ce soit pour identifier des noms de produits similaires, recommander des articles connexes ou faire correspondre des requêtes d'utilisateurs, la recherche de similarité textuelle joue un rôle crucial dans diverses applications. Nous allons explorer comment créer un système simple de recherche de similarité de texte en utilisant l'interface de BigQuery ML avec le modèle d'encodage de texte de Vertex AI.
Introduction aux Incorporations de Texte
Les incorporations de texte sont des représentations vectorielles denses de mots ou de phrases qui saisissent les relations sémantiques entre eux. En d'autres termes, des mots ou phrases de significations similaires seront représentés par des vecteurs proches dans un espace à haute dimension. Ces incorporations sont générées grâce à des modèles de langage puissants comme Vertex AI, qui est pré-entraîné sur un large corpus de données textuelles.
Configuration du modèle dans BigQuery
Nous allons vous guider à travers le processus de création d'un lien vers Vertex AI et de la configuration du modèle dans BigQuery. Nous commencerons par créer ce lien dans la région multi-région des États-Unis, étant donné que ces modèles sont, pour l'instant, disponibles uniquement dans cette région.
bq --location=us mk \
--connection \
--project_id=shikanime-studio-labs \
--connection_type=CLOUD_RESOURCE \
vertex_ai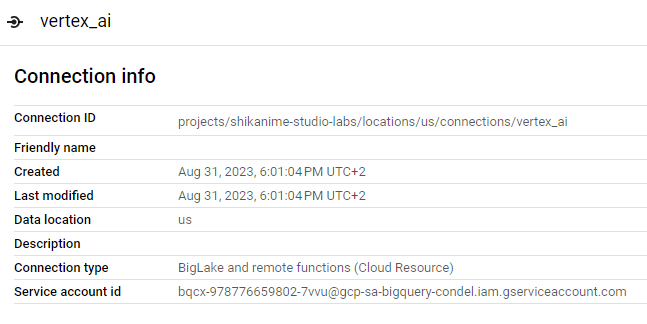
Afin que le service account puisse ensuite appeler l'API Vertex AI, nous devons lui attribuer au moins le rôle Vertex AI User :
gcloud projects add-iam-policy-binding shikanime-studio-labs \
--member=serviceAccount:bqcx-978776659802-7vvu@gcp-sa-bigquery-condel.iam.gserviceaccount.com \
--role=roles/aiplatform.userEnsuite, il nous faudra créer un ensemble de données pour stocker le modèle, ainsi que les différentes tables par la suite :
bq --location=us mk \
--dataset \
shikanime-studio-labs:text_search
Ensuite, nous allons procéder à la création du modèle dans BigQuery en utilisant la liaison que nous avons précédemment créée :
CREATE OR REPLACE MODEL
`shikanime-studio-labs.text_search.vertex_ai_text_embedding`
REMOTE WITH CONNECTION `us.vertex_ai`
OPTIONS(REMOTE_SERVICE_TYPE="CLOUD_AI_TEXT_EMBEDDING_MODEL_V1")
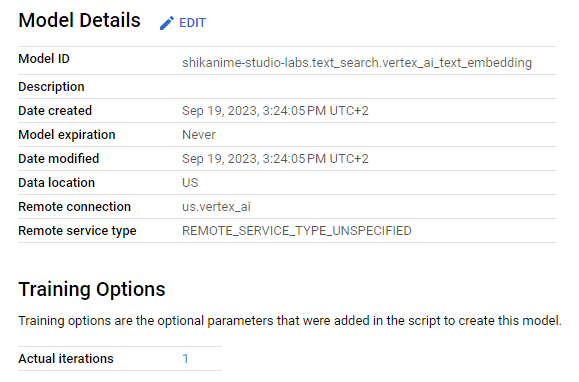
Dans cette section, nous avons mis en place une liaison qui remplit deux fonctions essentielles : elle nous permet d'établir une connexion externe pour interagir avec Google Cloud depuis BigQuery, ce qui implique la création automatique d'un compte de service et la définition des autorisations IAM.
En parallèle, nous avons enregistré le modèle dans BigQuery. Grâce à cette configuration, nous sommes désormais prêts à générer directement des incorporations de texte dans BigQuery, ce qui nous permettra d'effectuer efficacement des recherches de similarité de texte et de mener à bien d'autres tâches liées au traitement du langage naturel.
Création des Incorporations de Texte dans BigQuery
À des fins de démonstration, nous utiliserons un ensemble de données d'article de la BBC.
CREATE OR REPLACE TABLE
text_search.text_samples AS (
WITH
samples_raw AS (
SELECT
FARM_FINGERPRINT(title) AS id,
TRIM(LOWER(body)) AS content
FROM
`bigquery-public-data.bbc_news.fulltext`
LIMIT
100),
samples_with_index AS (
SELECT
ROW_NUMBER() OVER (PARTITION BY id) n,
*
FROM
samples_raw)
SELECT
* EXCEPT(n)
FROM
samples_with_index
WHERE
n = 1
ORDER BY
id)Nous employons le modèle créé plus tôt pour générer des incorporations de texte pour le contenu de ces articles.
CREATE OR REPLACE TABLE
text_search.text_embeddings AS (
SELECT
*
FROM
ML.GENERATE_TEXT_EMBEDDING(
MODEL text_search.vertex_ai_text_embedding,
TABLE text_search.text_samples,
STRUCT(TRUE AS flatten_json_output)))
Calcul des Similarités de Texte
Une fois que nous avons les incorporations de texte prêtes, nous pouvons procéder au calcul de la similarité entre différents textes. Nous utiliserons la métrique de similarité cosinus, qui mesure le cosinus de l'angle entre deux vecteurs. Plus le cosinus de similarité est proche de 1, plus les textes sont similaires.
CREATE OR REPLACE TABLE
text_search.text_similarities AS (
WITH
pairs AS (
SELECT
a.id AS id,
a.text_embedding AS embedding,
b.id AS candidate_id,
b.text_embedding AS candidate_embedding,
FROM
text_search.text_embeddings a
INNER JOIN
text_search.text_embeddings b
ON
a.id < b.id)
SELECT
id,
candidate_id,
ML.DISTANCE(
embedding,
candidate_embedding,
"COSINE") AS cosine_similarity
FROM
pairs)Dans le script SQL ci-dessus, nous utilisons une auto-jointure pour créer des paires d'incorporations de texte, en évitant les calculs redondants en nous assurant que nous ne calculons la similarité qu'une fois pour chaque paire unique. La similarité cosinus est ensuite calculée à l'aide de la fonction "ML.DISTANCE", et les résultats sont stockés dans une nouvelle table.
Récupération des Meilleures Similarités
Enfin, nous pouvons récupérer les textes les plus similaires pour chaque entrée dans l'ensemble de données. Pour ce faire, nous regroupons les résultats par l'ID du texte d'origine et utilisons la fonction "ARRAY_AGG" pour collecter les ID de candidats les plus similaires ainsi que leurs scores de similarité cosinus.
CREATE OR REPLACE TABLE
text_search.text_best_matches AS (
SELECT
id,
ARRAY_AGG(STRUCT(
candidate_id,
cosine_similarity)
ORDER BY
cosine_similarity
LIMIT
5) AS candidate_ids
FROM
text_search.text_similarities
GROUP BY
1)La table contiendra les ID des textes d'origine ainsi que les ID de leurs textes les plus similaires et leurs scores de similarité cosinus correspondants, qui peuvent être utilisés pour classer et afficher les correspondances les plus pertinentes.
Pour obtenir les articles similaires à "The gaming world in 2005", nous pouvons simplement exécuter cette requête :
WITH
sample AS (
SELECT
*
FROM
text_search.text_best_matches
WHERE
id = FARM_FINGERPRINT("The gaming world in 2005"))
SELECT
b.title
FROM
sample,
UNNEST(candidate_ids) AS a
JOIN
`bigquery-public-data.bbc_news.fulltext` b
ON
a.candidate_id = FARM_FINGERPRINT(b.title)Comme on peut le constater, non seulement le sujet semble correct, mais la chronologie semble correspondre parfaitement à environ 2005, comme c'est le cas avec Halo 2 que j'attendais avec impatience !
[{
"title": "Halo fans\u0027 hope for sequel"
}, {
"title": "Nintendo DS aims to touch gamers"
}, {
"title": "DS aims to touch gamers"
}, {
"title": "Nintendo handheld given Euro date"
}, {
"title": "No half measures with Half-Life 2"
}]Conclusion
Dans cet article, nous avons exploré comment construire un système simple de recherche de similarité de texte en utilisant le modèle pré-entraîné de Vertex AI, et cela, sans aucun coût de maintenance.
En calculant la similarité cosinus entre les incorporations de texte, nous pouvons trouver efficacement des textes similaires pour diverses applications, telles que les recommandations de produits, les recommandations de contenu ou l'expansion des requêtes de recherche.
La recherche de similarité de texte est une technique puissante qui ouvre la porte à une large gamme d'applications de traitement du langage naturel. À mesure que vous poursuivez votre parcours NLP, vous pourrez améliorer davantage le système avec des modèles plus sophistiqués et des techniques de réglage fin.
Une stratégie prometteuse consisterait à intégrer directement un modèle SavedModel ou ONNX, permettant ainsi d'éviter les coûteuses requêtes réseau vers Vertex AI. Cette stratégie éliminerait une série d'opérations de désérialisation et de sérialisation, un goulot d'étranglement dans tout projet de traitement de données nécessitant une mise à l'échelle et une gestion économique des ressources.



![[04] Data Engineering avec Gemini CLI](/content/images/size/w1304/2025/10/Gemini_CLI_Data_Engineering.png)



{kind=link}