
Au cours des différentes formations dbt que j’ai dispensées, et bien sûr chez les clients auprès desquels je suis intervenu, j’ai constaté différentes organisations possibles de projets dbt et suis récemment tombé sur une problématique de mutualisation de macros dans une organisation multi-domaines et multi-projets.
Du côté de la granularité des projets dbt, il y a deux façons de faire aux extrémités:
- Un seul gros (ou très gros) projet dbt (j’ai vu des projets avec 1500 modèles et 10000 tests)
- Beaucoup de petits/moyens projets dbt
Et entre les deux évidemment, différents niveaux de regroupement possibles. C’est le cas chez un de mes clients actuels, avec cette organisation:
1 Data platform > 12 Domaines > 500 Projets
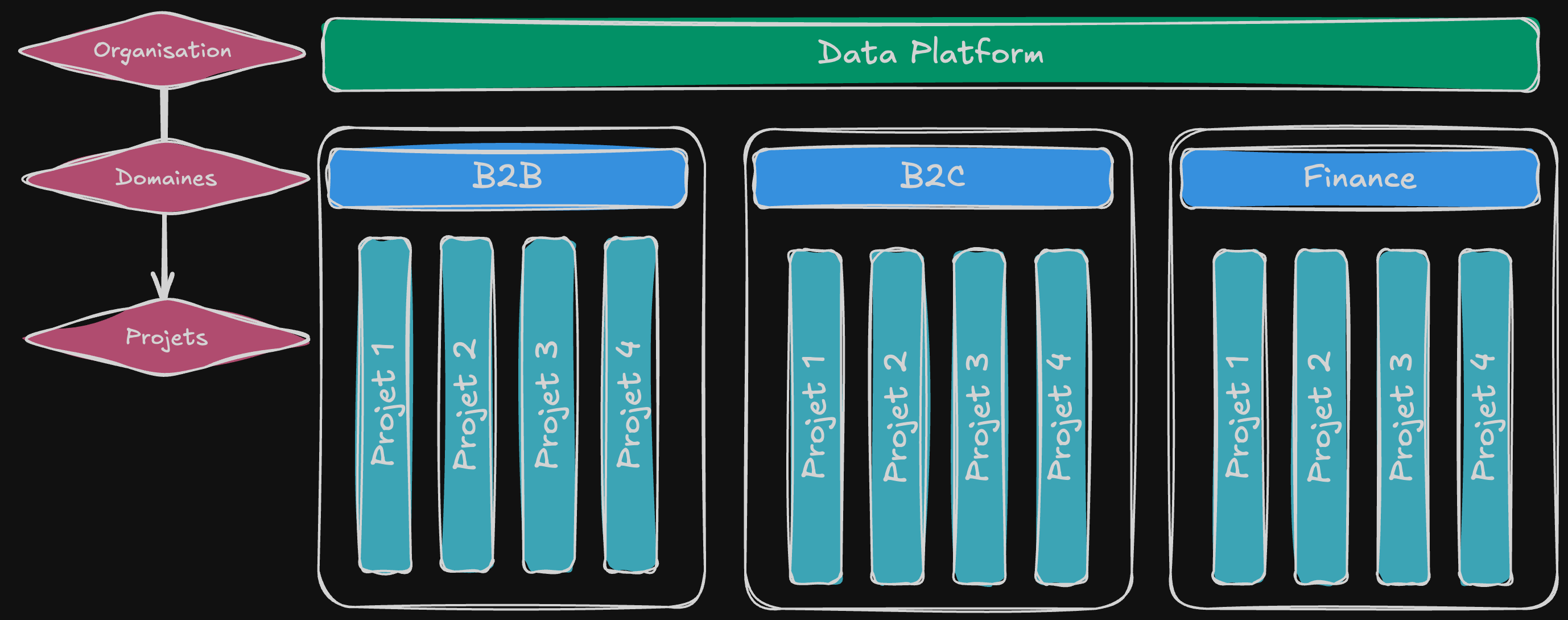
Les projets peuvent être de type Data Lake, Data Warehouse ou Data Mart et il y a du code commun utilisé dans quasiment la totalité des cas. Souvent répétées dans chacun des projets : les mauvaises habitudes ont la vie dure.
C'est un orchestrateur, comme Airflow/Composer ou Kestra, qui se charge d'exécuter les jobs dbt après une phase d'ingestion via des outils comme Airbyte ou Fivetran.
Il se trouve que ce code peut avoir un intérêt à être mutualisé au niveau le plus haut de la Data Platform. Sauf qu’il faut parfois le personnaliser avec des spécificités relatives à un domaine, et même parfois pour un projet précis.
Néanmoins, la plupart des projets utilisent une même base de code et il est évident qu'un package dbt est la bonne stratégie à adopter pour distribuer et utiliser ce code commun.
Ce package dbt commun est maintenu par une équipe “platform” qui n’a pas vocation à gérer les spécificités des domaines ou des projets mais dont une partie du boulot est de fournir une base de code réutilisable très facilement pour tous les projets qui n’ont pas de besoin particulier.
Aussi, à partir de ce package générique mais ajusté aux besoins de l'organisation (une centaine de macros communes par exemple), il n'y a en réalité que très peu de macros qui doivent être modifiées dans les domaines ou les projets: le code commun va plutôt à tout le monde, sauf exceptions, évidemment.
Enfin, en plus des macros spécifiques à mon organisation qu’on invoquera dans le code avec le pattern “package.macro”, il y a aussi de nouvelles versions des macros génériques de dbt, comme la fameuse “generate_schema_name” qui n’est pas invoquée explicitement dans nos modèles mais par le moteur de dbt lui-même .
Alors comment faire pour mettre ce package en place, et notamment la surcharge des macros génériques ?
Le cas des macros classiques
dbt a une structure modulaire avec un code “core”, du code spécifique aux "adapters" (BigQuery, Snowflake, Redshift, etc.), le code du projet dbt sur lequel on travaille et aussi les packages que j’évoquais plus haut.
Imaginons une formule générique de calcul du chiffre d'affaires que l'on veut utiliser dans tous nos projets. Embarquer cette formule dans une macro “compute_turnover”, dans notre package “acme_dbt” et importer ce package dans nos projets permettra donc d’appeler la macro avec le code ci-dessous par exemple:
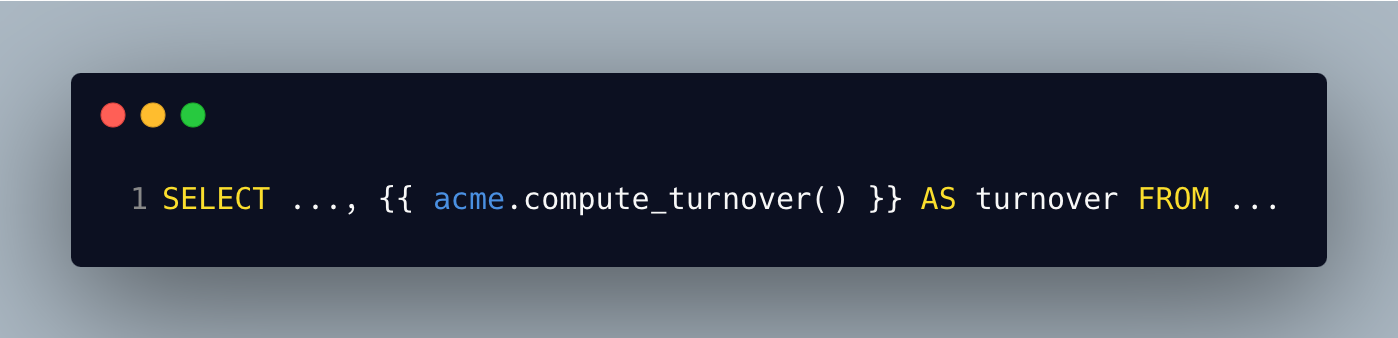
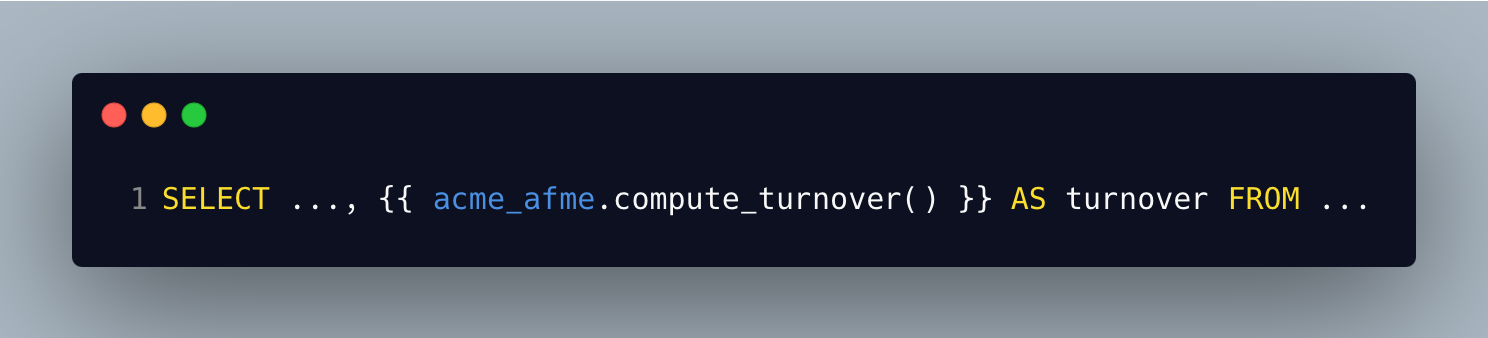
Si cette macro est toujours la même dans tous les projets sauf dans le domaine “afme” (Africa-Middle-East), on pourrait opter pour faire une macro spécifique via un package dédié à ce domaine et alors l’appeler avec le préfixe “acme_afme” par exemple (ce préfixe est le nom du package).
Notons que ce package “acme_afme” peut avoir comme dépendance le package “acme” de l’organisation et lui-même appeler des macros de ce package ascendant.
On aurait donc une macro “compute_turnover” dans notre package d’organisation, une macro “compute_turnover” dans notre domaine, et on l'appellerait cette fois avec le code:
Enfin, si dans mon projet, qui fait partie du domaine afme, j’ai besoin d’appeler une macro encore plus spécifique, je peux la définir au niveau projet et l’appeler sans utiliser de préfixe, par exemple avec le le code suivant:
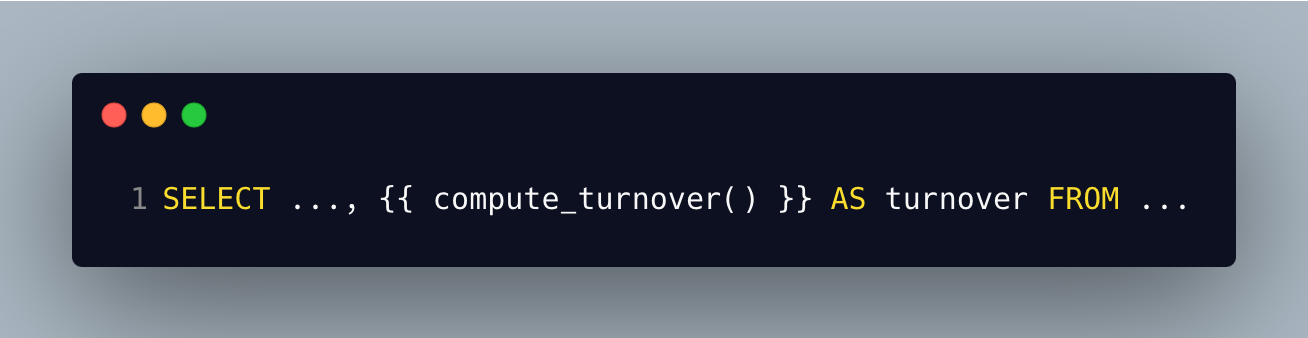
Des exemples classiques de variantes de macros génériques peuvent inclure un changement dans des valeurs par défaut, l’ajout d’arguments supplémentaires, la gestion de valeurs de tests, etc.
J'en profite pour rappeler que documenter ses macros, leurs arguments et mettre à disposition cette documentation est très important pour la maintenabilité des projets, et qu'abuser des macros sous prétexte de vouloir faire du code DRY ne doit pas pour autant nuire à la lisibilité – c'est une question d'équilibre !
Et les macros internes à dbt alors ?
Quand on parle de macros internes à dbt, on parle des macros “systèmes” comme generate_schema_name ou create_table_as par exemple. Ces macros sont définies dans le moteur dbt, déjà surchargées si nécessaire par le code de l’adapter. Mais on veut aussi pouvoir les surcharger pour tous les projets de notre organisation sans avoir à les redéfinir dans chacun d’eux.
Parmi les macros à implémenter, on trouve entre autres la possibilité de forcer au sein de toute l’organisation un pattern de génération de noms de schéma / dataset. Toujours convertir en majuscules, interdire des noms de datasets trop longs ou en mode camelCase, etc. Peu importe la logique tant qu’on peut la coder dans une macro dbt.
Le souci avec les macros génériques, c’est qu’on ne les invoque pas directement: c’est le moteur de dbt qui les utilise lors de son exécution pour matérialiser les tables, les vues, etc. On n’écrit pas soi-même dans le code “generate_schema_name(....)”, et donc on ne peut pas aller préciser un suffixe de package à utiliser, qu’il soit au niveau organisation ou domaine.
Quand on crée un modèle “model.sql”, c’est le moteur de dbt qui sait qu’il doit aller le matérialiser dans un “projet.dataset.model”, et pour cela il utilise les fameuses macros, la configuration et le profil issus des fichiers dbt_project.yml et profiles.yml.
Pour aller surcharger automatiquement ces macros via un package, on va utiliser la fonction de dispatch dans le namespace “dbt” et donc demander à dbt d’aller chercher la macro dans un ordre précis puis de prendre la première qu’il trouve.
Imaginons donc qu’on a un projet “sales” dans lequel on va importer un package d’organisation “acme” via lequel on veut écraser la macro par défaut de dbt “generate_schema_name”. Dans le code package, on déclare la macro comme ceci:
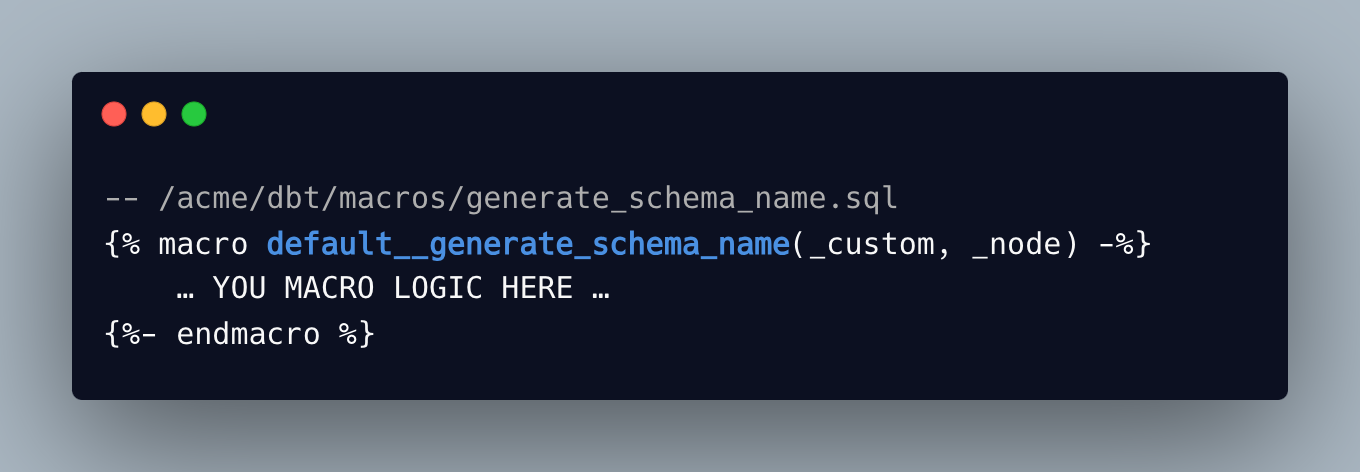
Attention, le nom de cette macro doit bien être préfixé avec “default__” (il y a bien 2 underscores) car on veut qu’elle s’applique quel que soit l’adapter utilisé. Si on voulait qu’elle soit spécifique à Redshift par exemple, on préfixerait son nom avec “redshift__”.
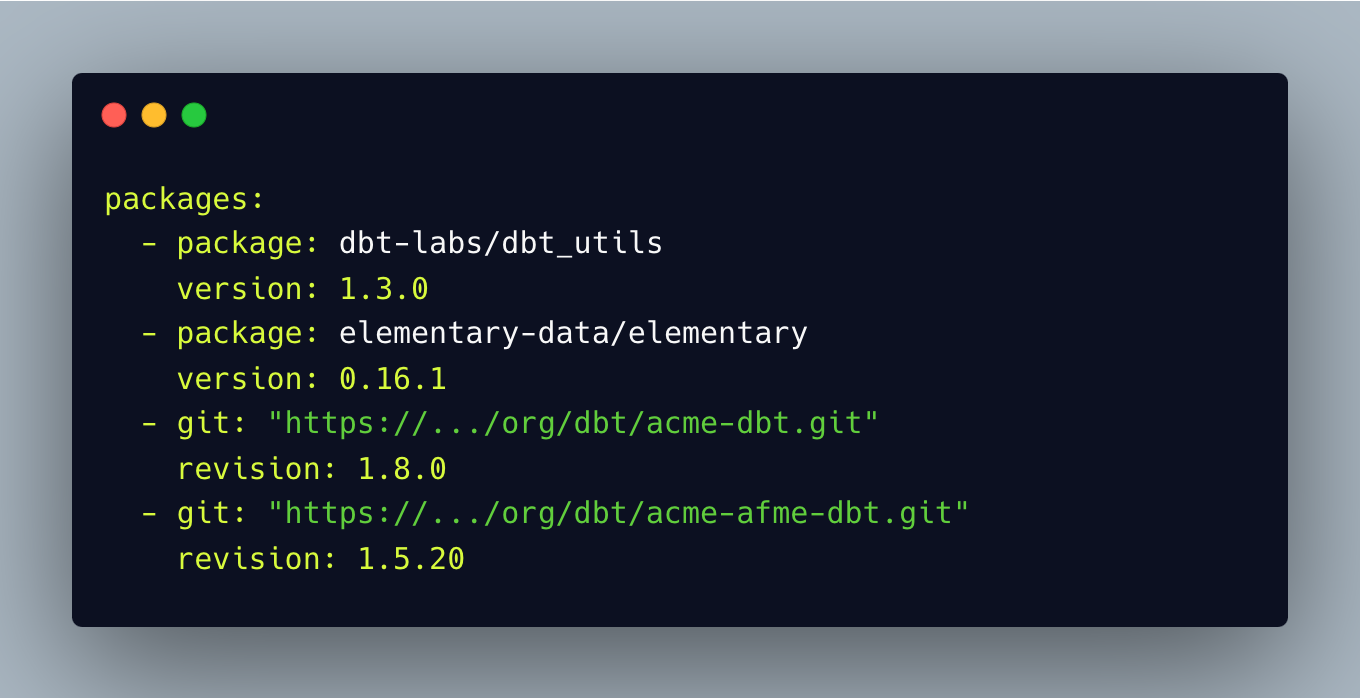
On déclare ensuite le package dans le fichier packages.yml du projet dbt dans lequel on veut utiliser la macro, et on vient aussi modifier la configuration dans le dbt_project.yml, comme ceci:
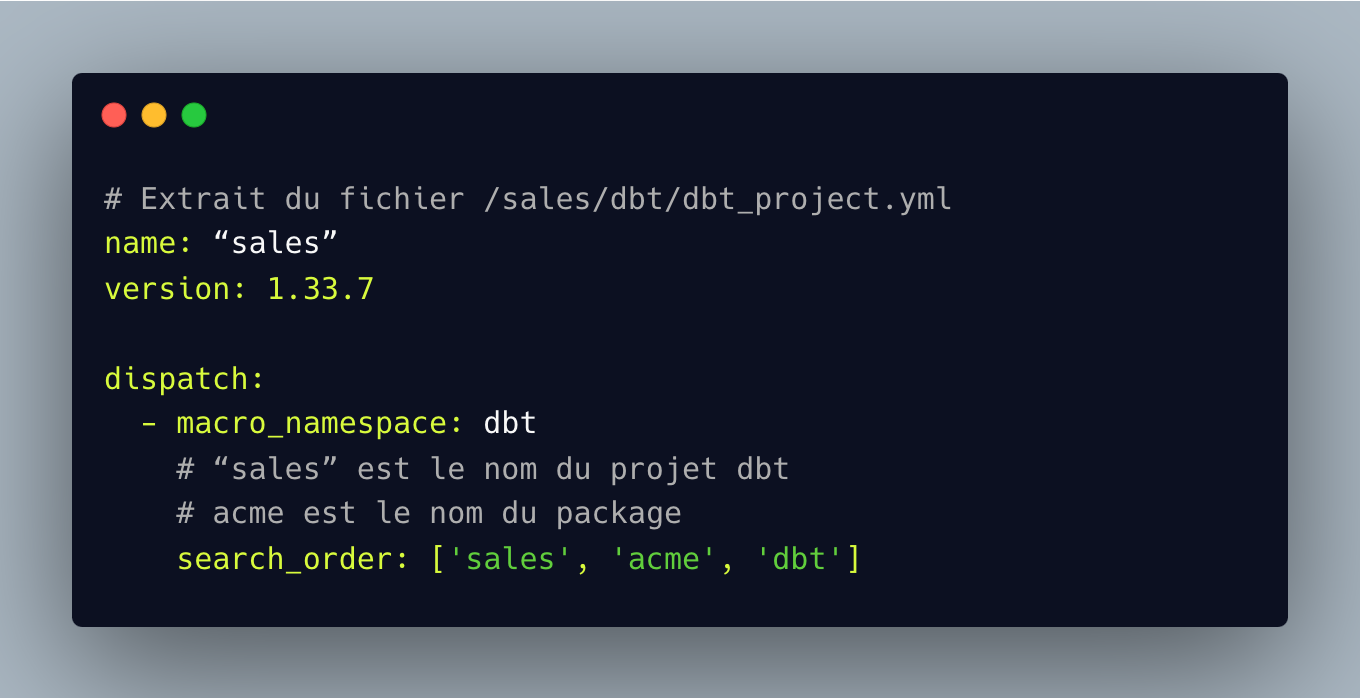
L’ordre dans le search_order est très important: on demande à dbt de rechercher les macros du namespace “dbt” d’abord dans le projet, puis dans le package “acme” puis dans le code de dbt core. Ainsi, si je surcharge la macro generate_schema_name directement dans mon projet, c’est elle qui sera utilisée. Sinon, ça sera celle du package “acme”, et s’il n’y a pas de surcharge de la macro, alors celle de dbt core sera utilisée.
Pour finir la mise en place, on peut même envisager un package intermédiaire au niveau du domaine. Ce package devrait être déclaré dans le dispatch en ajoutant, par exemple, "acme_b2b" entre "sales" et "acme" dans le cas d'un package dédié au domaine B2B. Il contiendrait une version personnalisée de la macro generate_schema_name et viendrait donc surcharger à son tour la macro du package de l’organisation.
Pour tester rapidement que tout fonctionne, il suffit de modifier le comportement de la macro dans le package, et la supprimer en local pour s’assurer qu’elle est bien récupérée et appliquée. Et le tour est joué. Reste à gérer au niveau de la CI le build des images dbt avec les bons droits pour aller lire les packages privées... mais ça, c’est une autre histoire !
Conclusion
Cette méthode de gestion des macros dbt répond à un défi majeur : concilier standardisation à l'échelle de l'entreprise et flexibilité au niveau des projets individuels. La mutualisation du code via des packages dbt, combinée à la possibilité de surcharger les macros à différents niveaux, offre une cohérence globale et une personnalisation locale pour construire sur une base de code partagée et correctement maintenue.
Références :
dbt custom schemas
dbt packages
dbt dispatch



![[04] Data Engineering avec Gemini CLI](/content/images/size/w1304/2025/10/Gemini_CLI_Data_Engineering.png)



{kind=link}