
On emploie souvent les termes IA, Machine Learning et Deep Learning dans les conversations de développeurs et de technophiles. Cependant, même si ces termes sont proches, ils recouvrent des cas d'usage et des complexités différentes.
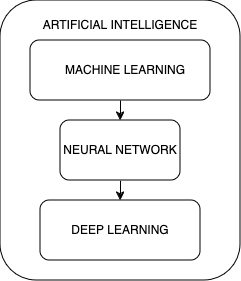
L'Intelligence Artificielle et le Machine Learning
L'Intelligence Artificielle recouvre de nombreux contextes emboîtés les uns dans les autres.
Tout d'abord, il y a le Machine Learning qui grâce à un historique de données représentatif du phénomène à modéliser sera capable de classer de nouvelles données inconnues et de leur attribuer la catégorie la plus probable en fonction du pattern de données.
Exemple
Prenons le cas d'une tâche de classification qui déciderait s'il faut commander ou non une pizza pour le dîner de ce soir 🍕.
Dans ce cas, les valeurs seraient :
- 0 : "pas de pizza" ou,
- 1 : "bien sûr, avec de l'ananas".
Des features pouvant décrire ce phénomène pourraient être par exemple :
Vais-je gagner du temps en commandant plutôt qu'en cuisinant ?
- 1 : "je gagne du temps"
- 0 : "je ne gagne pas de temps"
Est-il raisonnable pour ma santé de manger cette pizza ?
- 1 : "tout à fait, il y a de l'ananas" et
- 0 : "ne nous voilons pas la face bien sûr que non"
Est-ce une décision sensée économiquement ?
- 1 : "oui, j'ai un bon de réduction" et
- 0 : "non pas vraiment"
Dans ce cas, notre nouvelle d'entrée serait un input [1,0,1]. Ici, des valeurs binaires ont été prises par simplicité.
En plus de cela, nous devons ajouter pour chacune des variables d'input un poids correspondant à l'importance de chacun des facteurs. Par exemple mon temps à de la valeur, P=5, je tiens à ma ligne, P=3, cet achat ne va pas me ruiner, P=2.
Enfin, en utilisant une combinaison de ces facteurs et une fonction d'activation, nous pourrons décider s'il faut acheter cette pizza ou non :
P1I1 + P2I2 + P3I3 - Threshold* (*la threshold correspond à une limite fixée par le développeur de l'IA, un seuil à franchir notre fonction d'activation fixée à 5 dans cet exemple)
(1x5) + (0x3) + (1x2) - 5 = 2
2 > 0 PIZZA CE SOIR 🍕
L'Intelligence Artificielle et le Deep Learning
Ceci est un exemple de Machine Learning. Mais quelle est la différence avec le Deep Learning ? Tout simplement, le nombre de features nécessaires pour décrire la donnée.
Typiquement, le Deep Learning se distingue lorsque le modèle comprend plus de trois couches entre la couche d'entrée (input) et celle de sortie (output).
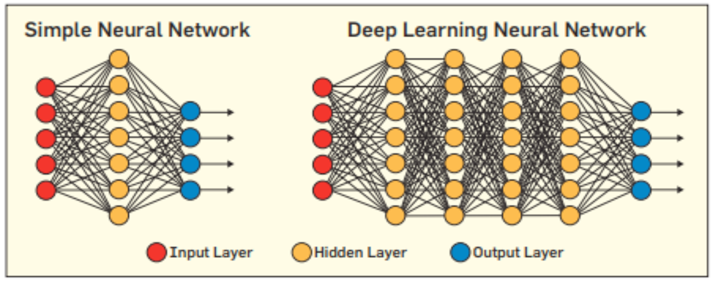
Le Machine Learning nécessite souvent une intervention humaine, par exemple pour créer un dataset de classification entre tacos, hotdogs et pizzas. On peut y ajouter des features variées, telles que :
- les dimensions,
- le poids,
- le nombre de calories,
- les ingrédients,
- le temps de cuisson,
- ou encore le type de farine.
L'objectif est de décrire chaque point de données avec le plus d'informations possible pour faire émerger des patterns spécifiques à chaque classe.
Le Deep Learning, en revanche, peut avoir en entrée des données brutes : images, textes, sons...
S'il y a suffisamment de données, il pourra extraire le pattern sous-jacent sans nécessiter d'autres interventions humaines qu'une labellisation des données.

Pour conclure
Si l'un n'est pas intrinsèquement supérieur à l'autre, il est important de bien isoler le cas d'usage pour lequel l'appliquer.
- Si les ressources sont limitées et que les données sont tabulaires et bien renseignées, le Machine Learning peut déjà offrir de bonnes performances pour un coût contrôlé.
- Si les données et cas d'usage sont plus variés, notamment pour des images, des modèles plus profonds et donc du Deep Learning peuvent être envisagés.






{kind=link}