
Pendant longtemps, les modèles de machine learning ont été conçus pour être hautement spécialisés dans un seul domaine, tels que le traitement automatique du langage naturel, la reconnaissance d'images ou encore les séries temporelles. Toutefois, le premier modèle à avoir franchi le pas de la pluridisciplinarité a été Text-to-Image, en essayant d'extraire le contexte du texte au lieu d'associer simplement des images à des "étiquettes". Lors d'une présentation à la conférence Devoxx France la semaine dernière, nous avons exploré en profondeur ces modèles et leur impact potentiel sur notre monde. Dans cet article, nous allons revenir sur les points clés de cette présentation et discuter de ce que nous avons appris sur les dernières avancées en matière de modèles Text-to-Image.
Choix historique : GANs
Les modèles de machine learning GAN (Generative Adversarial Networks) se composent de deux modèles de réseau de neurones: le générateur (Generator) et le discriminateur (Discriminator).
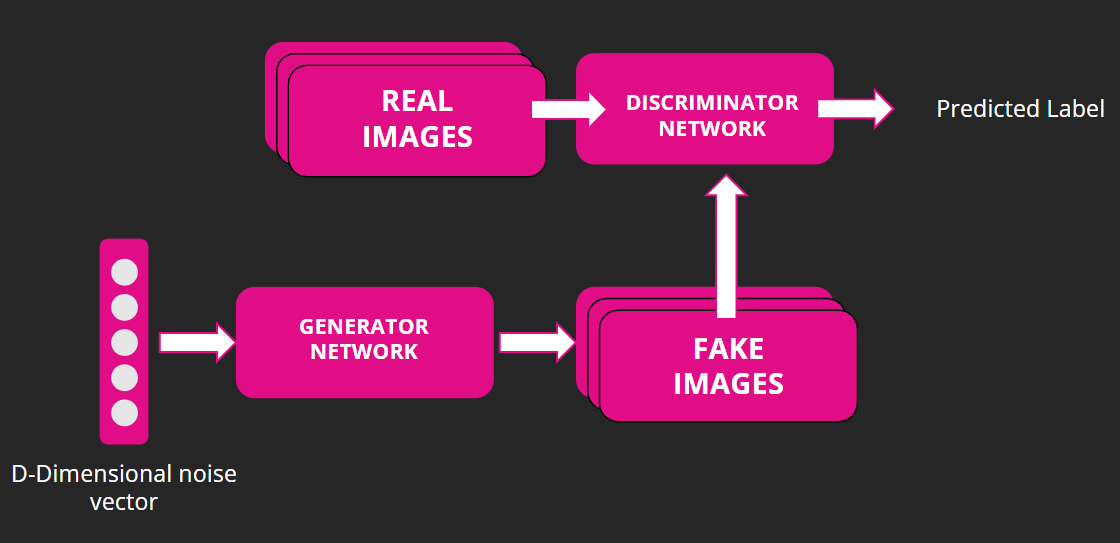
Le générateur crée de nouvelles données en partant d'un bruit de départ (un vecteur aléatoire). Il essaie d'apprendre à générer des données qui ressemblent aux données d'entraînement. Le discriminateur, pour sa part, est un classificateur binaire qui permet de déterminer si une donnée est réelle ou artificielle (c'est-à-dire générée par le générateur). Le but du discriminateur est d'apprendre à classifier les données avec précision en fonction de leur authenticité.
Les deux réseaux sont entraînés simultanément et en alternance. Le générateur produit une nouvelle série de données que le discriminateur évalue, puis le générateur ajuste sa sortie en fonction de la réaction du discriminateur, et ainsi de suite. Cette méthode d'entraînement permet au générateur d'apprendre à générer des données qui sont de plus en plus similaires aux données réelles, tandis que le discriminateur devient plus efficace pour identifier les données artificielles.
L'architecture GAN se base sur une compétition entre deux réseaux qui s'améliorent mutuellement, apprenant simultanément et itérativement. Le défi de l'entraînement d'un GAN consiste à maintenir un équilibre entre le Générateur et le Discriminateur. Il est important de surveiller attentivement le phénomène courant appelé "mode collapse", où le Générateur produit une typologie de données que le Discriminateur ne parvient pas à reconnaître. Dans ce cas, le Générateur continue de générer des images dans ce style, ce qui limite la diversité des images produites.
L’histoire compliquée : VQ-GAN + CLIP
Pour comprendre les dernières architectures de modèles derrière les outils comme Midjourney ou Dall-E il faut revenir à la base. La recherche a évoluée en partant de modèles simples comme les modèles AutoEncoder pour ensuite petit à petit améliorer et élargir les capacités des modèles génératifs.
Commençons par le début avec les modèles Autoencoder :
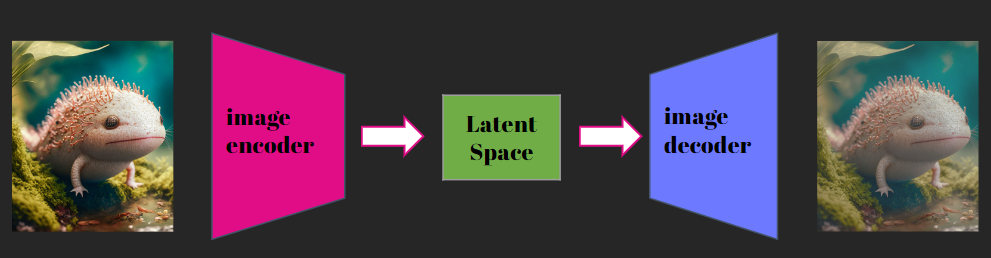
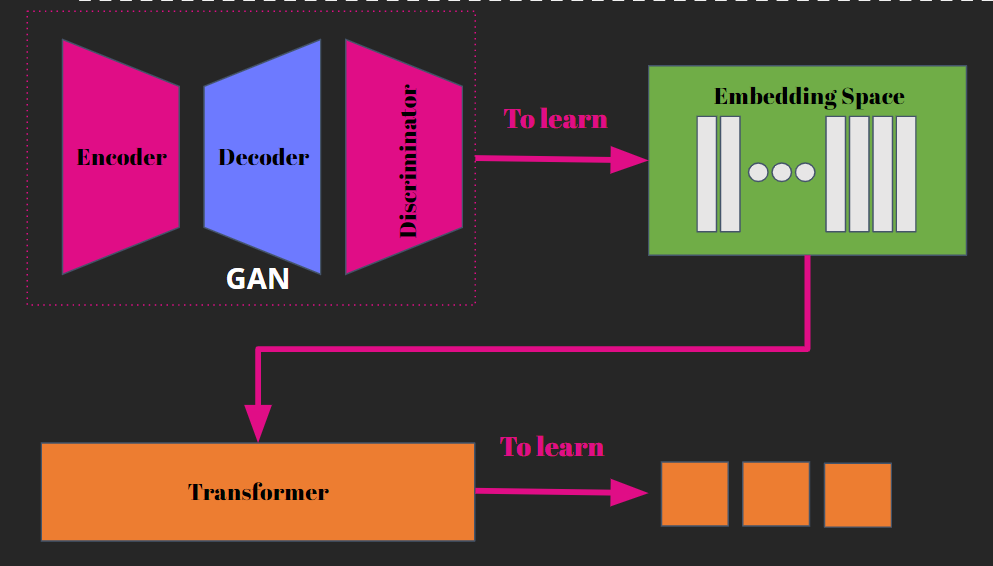
Cette architecture est composée de deux parties : un encodeur et un décodeur. L’encodeur est responsable de prendre une entrée de haute dimension et de la transformer en une représentation dans l’espace "latent" de faible dimension tout en gardant les informations importantes. Le décodeur a pour but de reconstruire l'entrée d'origine à partir de l’information de la représentation latente.
Le problème avec ces modèles est que l'espace latent est très dispersé, ce qui le rend difficile à utiliser pour la génération de textes.
Pour contrer ce problème, un nouveau modèle a été créé, le VAE pour - Variational Autoencoders. Comme les modèles Autoencoder, le but est de réduire la représentation des images dans un espace latent de plus faible dimension. La grande différence est que l’encodeur transforme l'entrée en une distribution de probabilité dans l'espace latent, qui représente la variation des données d'entrée. Cette distribution est généralement choisie pour être gaussienne, ce qui facilite l'apprentissage. Le décodeur prend ensuite la distribution latente et génère une sortie qui ressemble à l'entrée d'origine.
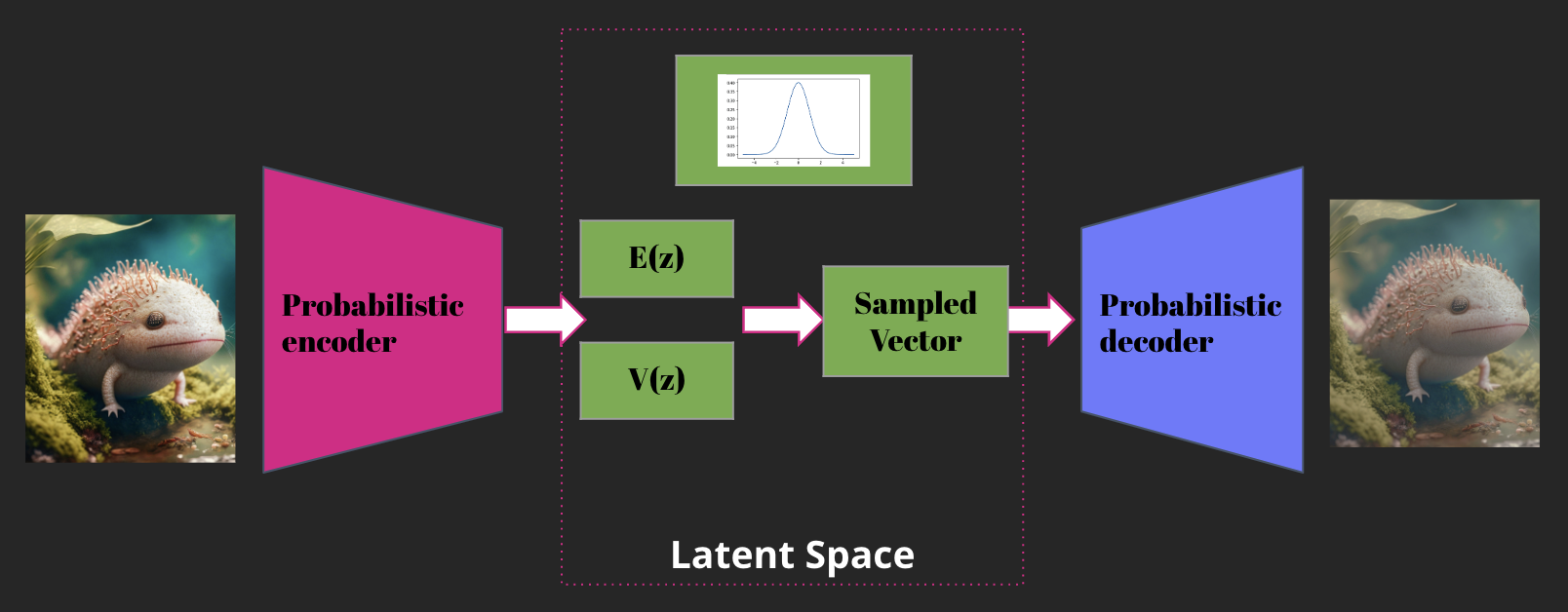
Avec ces modèles, nous avons une version de l’espace latent qui est beaucoup plus dense.
Afin de continuer à améliorer cette approche, un nouveau modèle nommé VQ-VAE (Vector Quantized Variational Autoencoder) a été développé. Cette approche étend les modèles VAE en intégrant une méthode de quantification vectorielle, ce qui permet d'améliorer la qualité de la représentation latente. Les modèles VQ-VAE sont composés d'un encodeur, un quantizeur et un décodeur. Tout comme les modèles VAE, l'encodeur transforme l'entrée en une représentation latente, mais au lieu de produire une distribution de probabilité, il produit un code quantifié. Ce code est ensuite utilisé par le décodeur pour produire une sortie. L’idée est double dans ces modèles : arriver à discrétiser la représentation d’une image et apprendre la fonction de distribution.
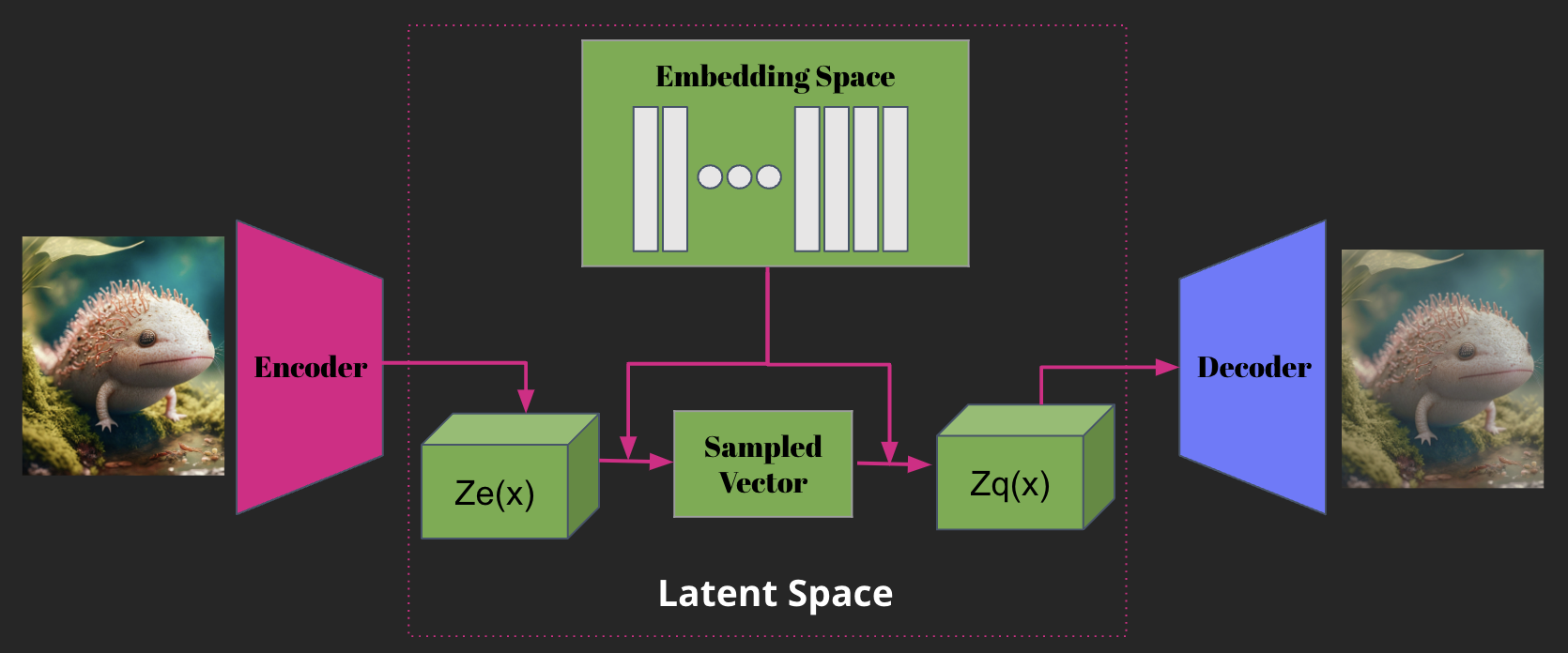
Pour conclure cette petite digression dans l'histoire des modèles génératifs, évoquons le modèle VQ-GAN. Cette approche combine la génération de l'espace latent avec les principes du GAN, ce qui permet de générer des images de haute qualité tout en préservant une diversité importante.
Le dernier chouchou de la communauté : Diffusion model
Les Diffusion models, qui ont leurs origines dans la physique, présentent à première vue des similitudes avec les GANs dans la mesure où ils génèrent des images à partir du bruit. Ce modèle introduit progressivement du bruit Gaussien, et en théorie, si l'on effectuait un nombre infini d'étapes, on obtiendrait en sortie du bruit parfait. Cependant, en informatique, l'infini est un peu long et les ingénieurs sont souvent impatients, donc on se limite généralement à environ 100-150 étapes.
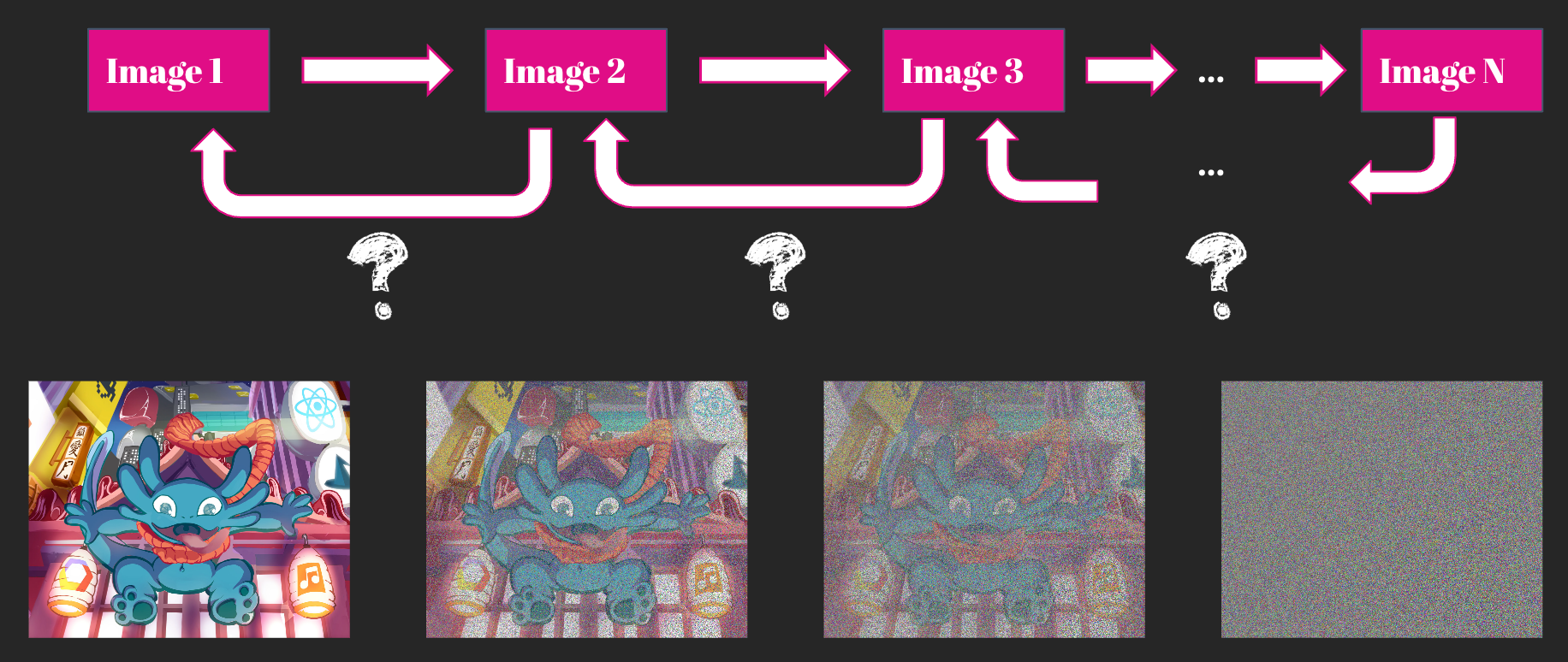
Et l’image ? À partir d’un prompt, une image est générée de manière itérative à partir du bruit. À chaque pas, en utilisant U-NET (un petit devoir à la maison, je vous laisse deviner d’où vient U 😉 ), on essaye de prédire tout le bruit à retirer de l’image actuelle pour obtenir l’image finale. Le modèle reste toutefois prudent, et retire à chaque fois qu’une partie du bruit avant de réévaluer la situation. Quant au prompt, il est encodé et ajouté de deux manières : concaténé à l’entrée avec l’image, ainsi qu'à chaque étape de U-NET à l’aide de cross-attention.
Il existe actuellement deux classes de Diffusion models :
- GLIDE (Guided Language to Image Diffusion for Generation and Editing) avec encore une fois deux variations différentes (et oui!) :
- Diffusion model guidé par un classificateur comme CLIP. A chaque itération, ce dernier fournit une indication sur la direction à prendre pour ajuster l'image et ainsi obtenir la meilleure correspondance prompt-image.
- “Classifier-free guidance” où nous n’utilisons plus de classificateur externe. En revanche, à chaque itération, nous ne générons pas une, mais deux images. Une image avec le prompt et une image sans le prompt. La différence entre ces deux images est ensuite calculée, permettant de déterminer la direction à prendre pour avancer l'image sans texte vers l'image avec texte.
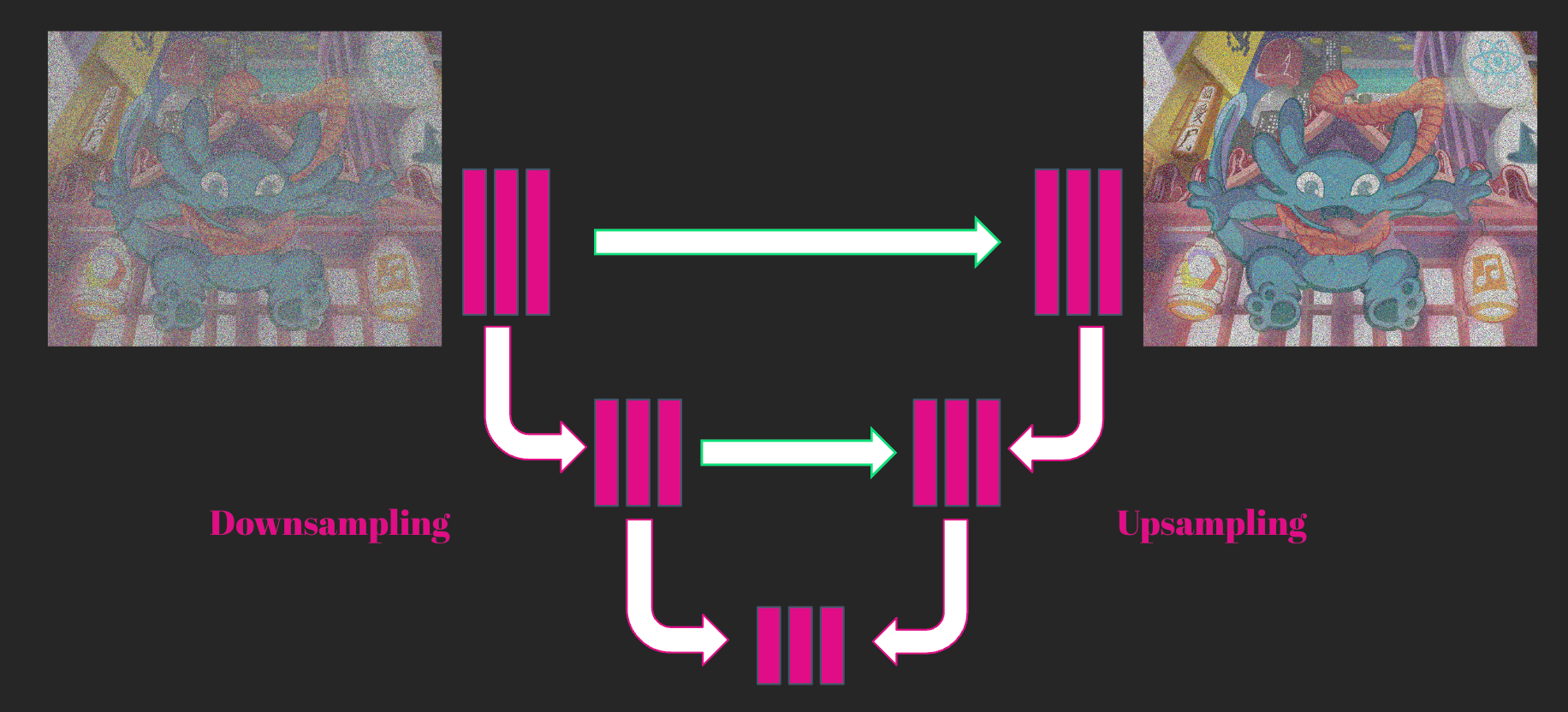
2. Latent Diffusion models constituent une solution au problème de dimensionnalité rencontré par les Diffusion models classiques qui opèrent dans l'espace des pixels, car le nombre de paramètres requis pour ces derniers explose rapidement ! Latent Diffusion model permet de compresser l’image à l’aide d’un auto-encodeur pour passer de l’espace des pixels à l’espace “latent”. Cela permet également de générer des images de plus haute résolution.
Un petit bonus : Latent Diffusion model le plus connu est Stability Diffusion, qui pour un modèle open-source produit des résultats assez bluffants ! Vous pouvez le tester gratuitement soit dans votre navigateur : Stable Diffusion Demo, soit avec quelques lignes de code sur votre machine* : Hugging Face Stable Diffusion.
*les exclusions s'appliquent, le GPU est quand même nécessaire. 💀
Et si on compare nos créations aux résultats d'un générateur d'images ? A vous de décider qui est la meilleure :

Si vous souhaitez découvrir d'autres temps forts du Devoxx 2023, je vous conseille l'article de Bertrand Mondolot.






{kind=link}