
Intro
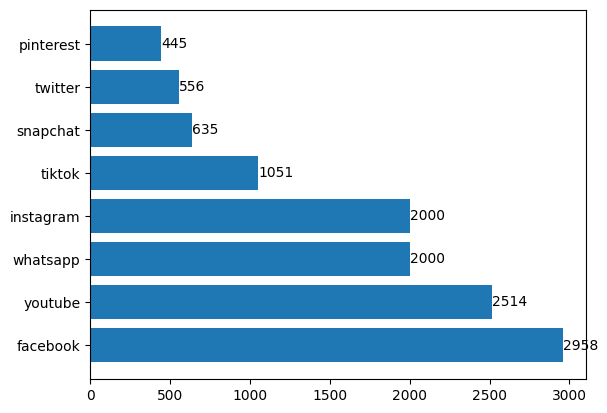
En 2023, Youtube est en passe de devenir l'une des plate-forme les plus populaires d'internet.
Selon Meltwater, c'est le deuxième site le plus visité et les utilisateurs y passent en moyenne 23h par semaine.
Sachant cela et ayant déjà réussi à automatiser une autre plateforme grâce à Python et Google cloud, j'ai décidé de ré-itérer l'expérience et d'utiliser Python et les Apis google pour générer des vidéos Youtube.
Youtube Automation
Les créateurs de contenus cherchent à augmenter leur productivité et la vitesse de production de leurs vidéos. Un moyen d'y parvenir rapidement est l'automatisation de la production. Ainsi, ils peuvent gagner du temps et se concentrer sur les aspects créatifs de leurs vidéos en automatisant les tâches les plus répétitives.
- Edition et post-production: L'édition de vidéos est un processus chronophage. Mais, il peut être accéléré grâce à des outils d'automatisation. Des outils qui proposent des fonctionnalités de traitement par lots, de modèles, de correction automatique des couleurs... permettent d'éditer plusieurs vidéos simultanément et d'assurer une qualité constante.
- Script-to-storyboard: Passer du script au storyboard est une étape cruciale de la phase de pré-production. Des scripts peuvent automatiser leur création via des modèles, des éléments visuels... Afin d'accélérer la création des scènes et d'améliorer la communication.
- Gestion des assets: Organiser et gérer les assets vidéos peut être difficile. Surtout dans le cas de production de grande échelle. Le tagging des métadonnées, renommage de fichiers, batch processing... rendent les tâches de recherche et tri plus faciles.
- Publication sur les réseaux sociaux: Faire la promotion de vos vidéos est crucial pour atteindre une audience plus large. Vous pouvez automatiser la distribution des vidéos sur les réseaux sociaux afin de gagner du temps et d'assurer une présence cohérente sur les plate-formes.
Ma stratégie
Ma stratégie : N'ayant pas davantage de compétences en création d'images, de vidéos ou de montage que lors de mon expérience précédente, j'ai décidé de réutiliser le contenu créé par des tiers. De plus, je voulais être le plus efficace possible en utilisant des scripts pour totalement automatiser le processus (étapes 1 à 3 citées précédemment). Je voulais limiter mon investissement à l'écriture de contenu texte (qui pourrait également être automatisé en utilisant des modèles LLMs). Fournir ce texte au script et attendre que la vidéo soit générée.
Stack technique

Python: Langage de scripting utilisé pour automatiser et orchestrer la création de vidéos.

Moviepy: est une librairie python qui permet aux développeurs d'éditer, manipuler et créer des vidéos facilement. Elle propose de nombreuses features permettant notamment de simplifier le cut, la concaténation, le redimensionnement et l'application d'effets sur des clips vidéos.

Beautifulsoup: Librairie python pour le web scraping et le HTML. Elle permet de naviguer dans les structures HTML, chercher des éléments spécifiques, extraire des informations des tags et attributs...

Google Text-to-Speech API: C'est un outil puissant de conversion de texte en parole ayant un rendu naturel. En intégrant cette API dans vos applications, vous pouvez générer du contenu audio dynamiquement à partir de contenu textuel.
Le Code
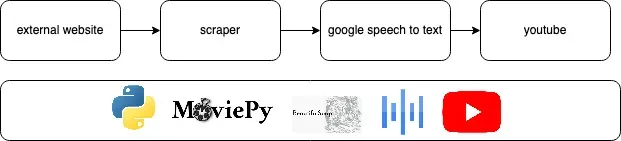
En utilisant BeautifulSoup et Python, le script va lire le texte d'une page web donnée en entrée. Il récupère le titre en h1 comme titre et sujet de la vidéo et lit le texte entre balises <p></p> en utilisant l'API Google Speech to Text. La qualité a beaucoup augmenté récemment et est bien moins 'robotique'. J'ai choisi 'fr-FR-Wavenet-A' qui me semblait être la plus naturelle.
def text_to_speech(text, audio_file):
client = texttospeech.TextToSpeechClient()
synthesis_input = texttospeech.SynthesisInput(text=text)
voice = texttospeech.VoiceSelectionParams(language_code="fr-FR",name="fr-FR-Wavenet-A", ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL )
audio_config = texttospeech.AudioConfig( audio_encoding=texttospeech.AudioEncoding.MP3 )
response = client.synthesize_speech(input=synthesis_input, voice=voice, audio_config=audio_config )
with open(audio_file, "wb") as out:
out.write(response.audio_content)Chaque bloc de texte va être envoyé à l'API Google Image où une image au hasard sera sélectionnée et téléchargée. Puis, en utilisant OpenCV, l'image est floutée et utilisée comme fond avant que l'image originale soit collée au-dessus. Ceci a été fait en suivant les conseils d'un ami monteur vidéo qui m'a dit que cela permet d'éviter les problèmes de format d'images qui peuvent être visuellement choquantes.
for paragraph in soup.find_all('p'):
query = str(paragraph.text)
url = 'https://www.google.com/search?q='+query+'&client=ubuntu&hl=en&sxsrf=ALiCzsbTbbiFtVOzggWBSmpnlZRKP2SycQ:1660670349607&source=lnms&tbm=isch&sa=X&ved=2ahUKEwi90ZuS78v5AhUKw4UKHQDNArIQ_AUoAnoECAIQBA&biw=1247&bih=1299&dpr=1'
filename = 'image_'+str(j)+'.jpg'
page = requests.get(url).text
soup = BeautifulSoup(page, 'html.parser')
k = 0
for raw_img in soup.find_all('img'):
link = raw_img.get('src')
if link and k < 1 and 'gif' not in link and link not in links:
urllib.request.urlretrieve(link, filename)
img = cv2.imread(filename, -1)
blur = cv2.blur(img,(5,5))
output = cv2.resize(blur, DSIZE, interpolation = cv2.INTER_AREA) x_offset = 320-(int(img.shape[0]/2))
y_offset= 180-(int(img.shape[1]/2))
print(filename)
output[y_offset:y_offset+img.shape[0],x_offset:x_offset+img.shape[1]] = img cv2.imwrite(filename, output)
k += 1
if k > 3:
break
text_to_speech(paragraph.text, "output_"+str(j)+".mp3")#
client = texttospeech.TextToSpeechClient()Le texte ad hoc est concaténé à l'image, et l'image reste à l'écran le temps que le bloc de texte adapté soit lu. Puis, en utilisant moviepy, un fade-in est ajouté entre les images.
for filename in os.listdir('.'):
if filename.endswith(".mp3"):
audio_value = MP3(str(filename))
audio[str(filename)] = math.ceil(audio_value.info.length)
audio_names.append(str(filename))
audio_names = sorted(audio_names)
img = []
base_dir = os.path.realpath(".")
for filename in os.listdir('.'):
if filename.endswith(".png") or filename.endswith(".jpg") or filename.endswith(".jpeg"):
img.append(filename)
img = sorted(img)Enfin, les vidéos résultantes sont concaténées pour créer une vidéo complète.
Résultats et limites:
Bien que le résultat soit intéressant, il est loin d'être concluant, la voix étant encore très robotique et sans émotion. De plus, des problèmes de son peuvent être entendus lorsque les différents clips sont concaténés. Ce projet est davantage adapté à des vidéos non professionnelles ou à des 'usines de vidéos' plutôt que pour des vidéos de haute qualité.
Pour avoir un aperçu :



![[04] Data Engineering avec Gemini CLI](/content/images/size/w1304/2025/10/Gemini_CLI_Data_Engineering.png)



{kind=link}