
L'informatique Serverless : quels changement pour les développeurs et les DSI ?
L'informatique Serverless, ou "informatique sans serveur", est une approche de développement et de déploiement d'applications qui change la manière dont les développeurs et les DSI gèrent l'infrastructure informatique. Malgré son nom, il est important de noter que le Serverless ne signifie pas l'absence de serveur. En réalité, les serveurs sont toujours présents, mais ils sont simplement invisibles pour les développeurs et les DSI.
Qu'est-ce que le Serverless ?
Dans une architecture Serverless, les développeurs ne se soucient plus du déploiement de leurs applications. Ils se concentrent uniquement sur leur code, tandis que l'infrastructure nécessaire pour exécuter leurs applications est gérée par un fournisseur de services cloud. Le déploiement de l'application se fait à partir du code de l'application à l'aide d'une simple commande.
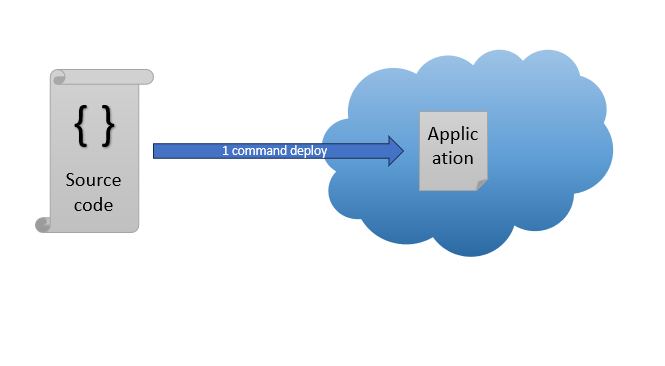
Pour les DSI, le Serverless signifie qu'ils n'ont plus à gérer d'infrastructure. Ils peuvent se concentrer sur d'autres tâches plus stratégiques pour eux, comme la gestion des données et la sécurité.
Le Serverless et le Cloud
Le Serverless est étroitement lié au cloud. En effet, le plein potentiel du Serverless ne peut être atteint qu'avec le cloud, car c'est la seule plateforme qui permet de s'abstraire totalement de l'infrastructure sous-jacente. Les grands fournisseurs de services cloud proposent ce type de service. De plus, la facturation se fait à la seconde de traitement, ce qui permet de réaliser des économies significatives. Lorsque le service n'est pas utilisé, il n'est pas facturé.
Le Serverless offre principalement deux façons de déployer des applications : en utilisant des fonctions ou des conteneurs.
Function as a Service (FaaS)
La première méthode est connue sous le nom de "Function as a Service" ou FaaS. Dans ce cas, le code est une simple fonction, plutôt petite, généralement écrite dans un langage courant comme TypeScript, Java, Python ou Go. Cette fonction est associée à un déclencheur, qui peut être un message dans une file de messages ou une requête HTTP. Ce dernier cas est particulièrement utile pour mettre en place facilement des backends HTTP. Il est important de noter que le temps d'exécution de la fonction doit généralement rester court, souvent moins d'une seconde (ceci est variable selon les plateformes). Des exemples de services FaaS incluent Google Cloud Function, Amazon Lambda et Microsoft Azure Function.
Conteneurs
Pour des applications plus complexes, on optera plutôt pour le déploiement de conteneurs. Ces derniers sont capables de gérer des requêtes ou des scénarios plus avancés. Le conteneur est poussé sur la plateforme et est déployé et mis à l'échelle automatiquement, sans que le développeur ait à se soucier de l'infrastructure sous-jacente. Parmi les principaux exemples de ce type de service, on peut citer Google Cloud Run, Microsoft Azure Container Apps et Amazon Fargate.
Ces deux modes de déploiement offrent une grande flexibilité et permettent aux développeurs de se concentrer sur le code de leurs applications, tout en bénéficiant de la puissance et de l'évolutivité du cloud.
L'approche "serverless" s'applique au-delà du déploiement de conteneurs ou de fonctions dans le cloud. Par exemple, les services de stockage en ligne tels que Amazon S3 ou Google Cloud Storage peuvent être considérés comme des plateformes "serverless", car leurs utilisateurs ne se soucient aucunement de l'infrastructure stockant leurs données. De la même manière, une plateforme fournissant des API entièrement managées est également considérée comme "Serverless".
Le Serverless doit-il obligatoirement être déployé sur le cloud ?
Du point de vue du DSI, la réponse est oui. Lorsque des applications fonctionnent sur une infrastructure propriétaire (quelle que soit la manière dont elles sont déployées), le DSI doit toujours maintenir cette infrastructure. Cependant, les équipes Ops peuvent mettre à disposition des équipes de développement une infrastructure Serverless qu'elles gèrent. Pour les développeurs, l'expérience est identique : ils déploient leurs applications à partir d'une simple ligne de commande.
L'infrastructure sous-jacente est généralement du Kubernetes, sur laquelle on vient poser une "couche" Serverless. Par exemple, on peut utiliser OpenFaaS pour du déploiement de Fonctions as a Service, ou encore KNative pour du déploiement en mode Container as a Service. On peut y adjoindre aussi BuildBacks, qui permet de construire facilement un conteneur directement à partir du code source (sans besoin de fournir un Dockerfile). Ces deux derniers outils sont d'ailleurs ceux utilisés par Google pour offrir son service CloudRun.
Un autre stack intéressante est Firecracker, stack serverless open source soutenue par Amazon, et sur laquelle se base leur deux plateformes AWS-Lambda et AWS-Fargate.
Pour la partie stockage, on peut citer Minio ou Seaweedfs offrant une solution de stockage compatibles S3 à installer sur votre propre cluster Kubernetes, permettant d'offrir à vos utilisateurs une expérience Serverless (accès au stockage par simple appels d'API).
L'utilisation du Serverless on-premises peut grandement faciliter la vie des développeurs, mais nécessite une bonne équipe Ops pour maintenir une architecture et des produits qui peuvent s'avérer complexes.
En conclusion, le Serverless est très interessant pour les développeurs et les DSI. Il permet de se concentrer sur le code et les tâches stratégiques, tout en offrant une grande flexibilité et des économies significatives lorsqu'il est utilisé sur le cloud. Quand il est déployé on-premises, la maintenance de l'infrastructure et des serveurs reste obligatoire, pas de magie !






{kind=link}