
Cinq chercheurs de l'université de Stanford se sont penchés sur les performances de sept détecteurs GPT. Leur étude, en prépublication, montre que les outils de détection ne sont pas fiables, surtout lorsque l'auteur n'est pas un locuteur natif de l'anglais.
Les non-anglophones sont affectés par un biais dans les détecteurs GPT
Le premier point à retenir de cette étude est qu'il existe un biais non négligeable entre les locuteurs natifs de l'anglais et les non-anglophones.
Pour arriver à cette conclusion, les détecteurs ont été soumis à des devoirs d'élèves américains de quatrième et des compositions du TOEFL. Le TOEFL étant le Test of English as a Foreign Language, les auteurs de ces compositions n'ont pas l'anglais comme langue maternelle. Si l'un de ces documents est classé par un détecteur comme généré par une IA, on parle alors de faux positif.
Comme l'illustre le graphique ci-dessous, les détecteurs ont classé plus de la moitié des TOEFL comme étant générés par une IA (taux moyen de faux positifs : 61,22 %), tandis qu'ils ont démontré une précision très élevée quant aux textes de quatrième.
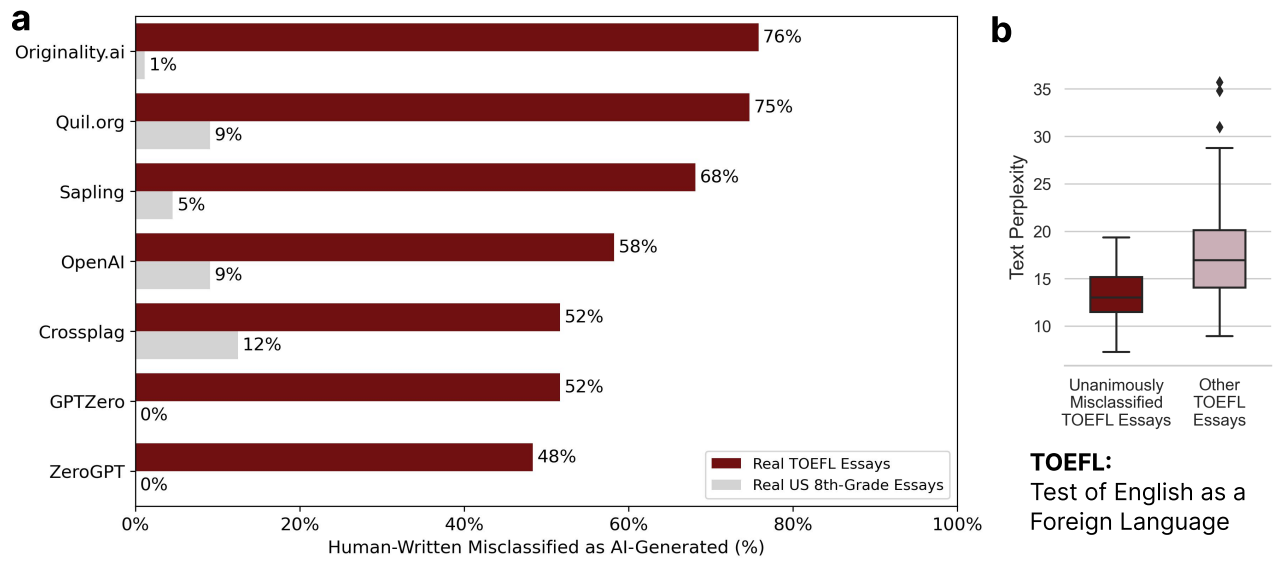
Selon cette étude, ce biais s'explique par « une variabilité linguistique [des textes] réduite par rapport à ceux rédigés par des locuteurs natifs ». En effet, le score de perplexité, mesure utilisée par les détecteurs qui évalue la richesse lexicale, est significativement plus faible pour les non anglophones par rapport aux anglophones. Ainsi, les textes avec une faible perplexité ont plus de chances d'être signalé comme généré automatiquement.
Les détecteurs actuels peuvent être facilement contournés par une consigne simple
Autre aspect à retenir de cette étude, contourner les détecteurs est une tâche aisée.
L'expérience a été de générer des compositions pour une candidature à des universités américaines avec ChatGPT, puis de reformuler ces essais en demandant à ChatGPT d'employer un langage littéraire.
Les résultats sont sans appel : si les détecteurs se débrouillent bien avec la première version générée, le taux de détection s'effondre avec les textes au langage plus soutenu.
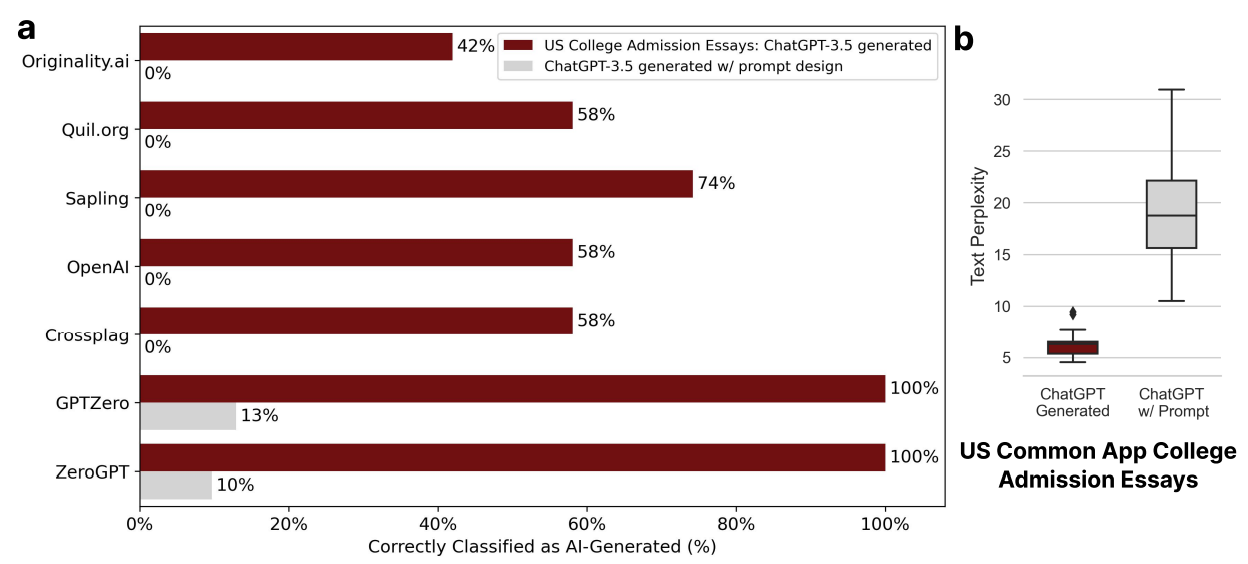
Encore une fois, la différence entre les deux jeux de données se trouve dans la perplexité. Reformuler avec un langage littéraire permet d'accroître la perplexité du texte, ainsi les détecteurs d'IA n'y voient que du feu.
Des suggestions pour faire face
Une fois le constat posé, les auteurs de l'étude proposent deux recommandations.
La première est d'éviter les détecteurs dans les milieux éducatifs, en particulier là où il y a un grand nombre de locuteurs non natifs de l'anglais. En effet, le taux élevé de faux positifs peut créer un préjudice à cette population.
La seconde suggestion est de ne plus se baser uniquement sur la perplexité et d'ajouter par exemple des techniques de tatouage numérique.
Vous trouverez l'étude complète sur les serveurs arXiv.




![[KubeCon 25] Comment sécuriser vos conteneurs Kubernetes avec Falco et Talon ?](/content/images/size/w1304/2025/04/falco2.png)


