
Dans les grandes entreprises utilisant le cloud, et plus particulièrement BigQuery sur Google Cloud Platform (GCP), la gestion des coûts devient un enjeu crucial. Les entreprises stockent des millions de tables et des pétaoctets de données. Au fil du temps, une grande partie de ces tables et données devient obsolète, n'étant ni utilisée ni archivée. Pourtant, les flux de données continuent souvent à les alimenter, entraînant des coûts inutiles.
Dans une démarche FinOps (Financial Operations), nous avons entrepris de quantifier ces dépenses liées au stockage de données inutilisées et aux traitements associés. Cet article explore comment analyser et visualiser ces données pour optimiser les coûts.
Qu'est ce que le FinOps ?
Le FinOps est une approche de gestion financière pour le cloud, combinant les pratiques de gestion financière et opérationnelle pour maximiser la valeur économique du cloud. En appliquant le FinOps, les entreprises peuvent mieux contrôler et réduire leurs dépenses tout en optimisant l'utilisation des ressources cloud.
Analyse des données inutilisées sur BigQuery
Représentation Graphique et Lineage
Pour comprendre l'impact des tables inutilisées et les flux de données inutiles, il est essentiel de visualiser les relations entre les différentes tables.
Le "lineage" permet de tracer l'origine et l’alimentation des données entre différentes tables.
Sur le graphe ci-dessous, on voit le lineage entre différentes tables avec les requêtes d’alimentation (CREATE TABLE AS SELECT, INSERT, UPDATE, MERGE) représentées par des arêtes noires. Aussi, des arêtes rouges représentent des requêtes d’utilisation (SELECT, CREATE VIEW, CREATE MODEL).
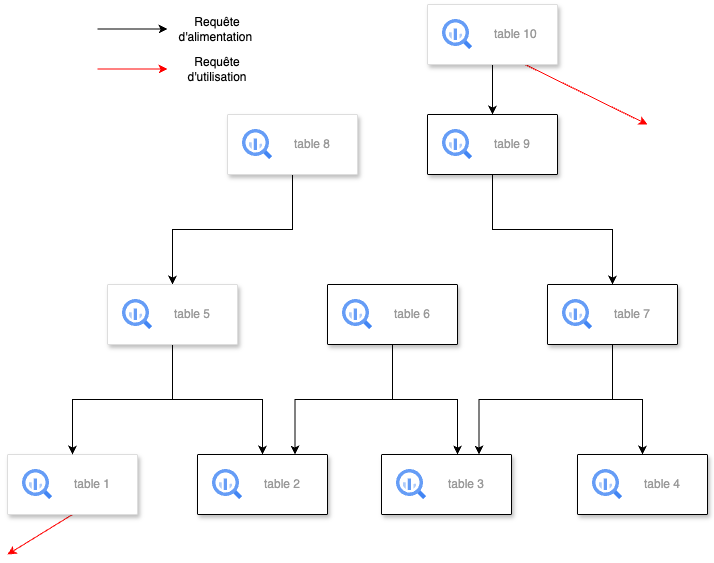
Algorithme de détection des tables inutilisées
Détection initiale :
Identifier les tables inutilisées comme les tables n’ayant pas été requêtées ni par une “requête d’alimentation” ni une “requête d’utilisation” depuis un certain temps défini préalablement. Ici, les tables 2, 3 et 4 ont été identifiées comme inutilisées contrairement à la table 1 qui a aussi été requêtée par une “requête d’utilisation”.
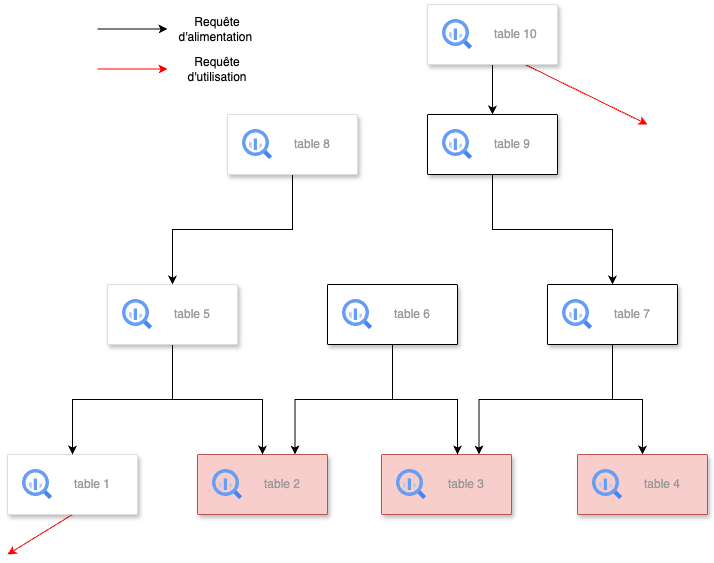
Propagation :
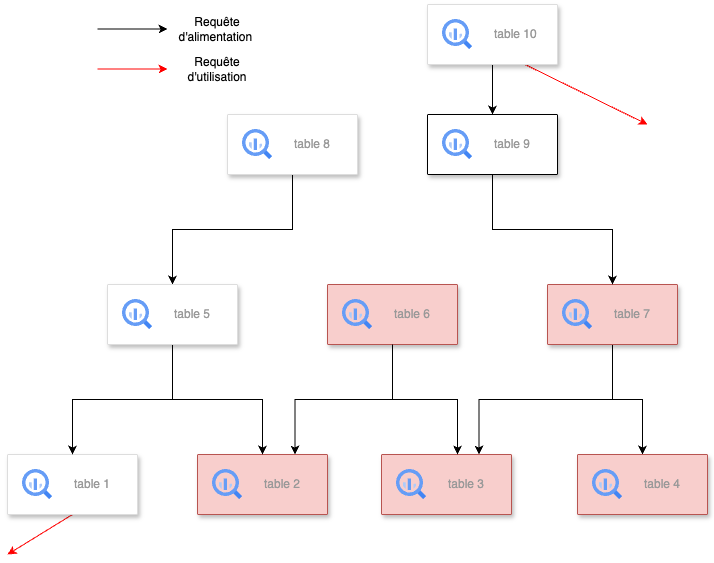
Ajouter les tables qui ont servi seulement à alimenter des tables inutilisées.
Dans l’exemple ci-dessous, les tables 6 et 7 ont été ajoutées parmi les tables inutilisées car elles n’ont servi qu'à alimenter les tables 2, 3 et 4. La table 5, ayant alimenté aussi la table 1 (utilisée), n'est pas ajoutée. Puis, à l’itération suivante, la table 9 a été ajoutée car elle servait qu’à alimenter la table 7 (inutilisée). La table 10 ne sera pas ajoutée car malgré qu’elle ait alimenté la table 9, elle a aussi été requêtée par une requête d’utilisation.
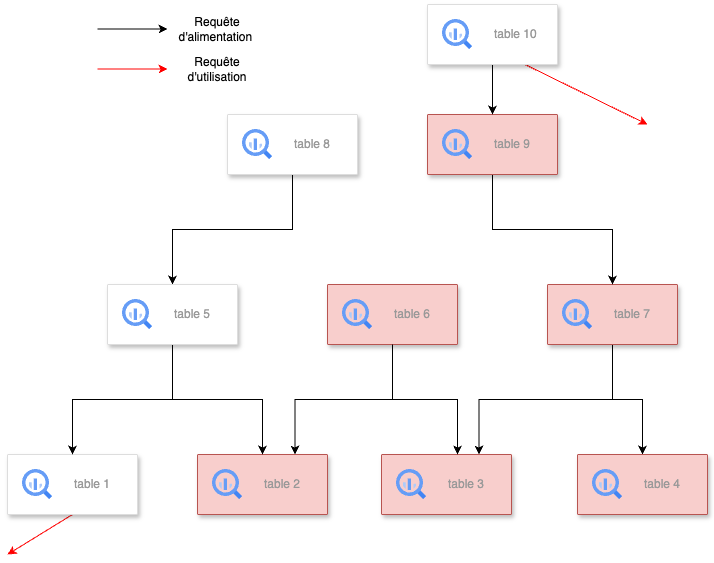
Création du lineage à partir des Logs de BigQuery
Les audit logs BigQuery fournissent des informations détaillées sur les opérations effectuées sur les tables. Ils vont servir à créer le “lineage” et à analyser l'utilisation des tables pour identifier celles qui ne sont pas utilisées.
Voici un exemple d’audit logs à partir de GCP :
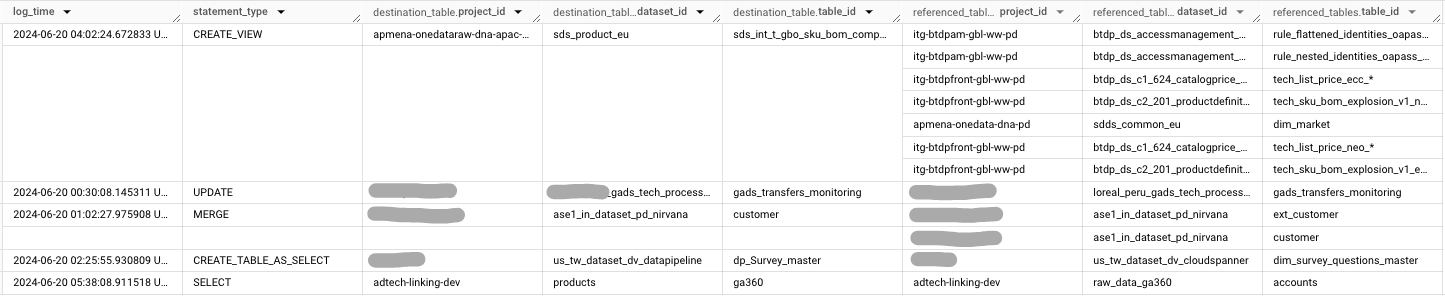
Les étapes suivantes construisent le lineage des tables à partir des logs de BigQuery, sachant que le lineage est construit à partir des logs sur les 6 derniers mois.
Étape 1 : Création de la table temporaire de lineage
La première étape consiste à créer une table temporaire appelée lineage qui contient les informations sur les requêtes effectuées au cours des six derniers mois, en particulier les types d'instructions SQL utilisées, les tables de destination, et les tables référencées dans chaque requête. La clause UNNEST est utilisée ici pour décomposer les tables référencées stockées sous forme de tableaux.
CREATE TEMP TABLE lineage AS (
SELECT DISTINCT
statement_type,
format(
'%s.%s.%s',
c.destination_table.project_id,
c.destination_table.dataset_id,
c.destination_table.table_id
) AS destination_table_name,
FORMAT(
'%s.%s.%s',
r.project_id,
r.dataset_id,
r.table_id
) AS ref_table_name,
@lv_last_log_time AS insert_timestamp,
FROM `project_id.dataset_id.raw_bq_jobs_complete_v1` c
CROSS JOIN
UNNEST(c.referenced_tables) r
WHERE log_time > TIMESTAMP(DATE_SUB(DATE(lv_last_log_time), INTERVAL 6 MONTH)) AND FORMAT('%s.%s.%s',r.project_id, r.dataset_id, r.table_id) IS NOT NULL
);Étape 2 : Identification des tables actives
Cette étape consiste à créer une table temporaire active_tables qui contient toutes les tables BigQuery actives dans l'organisation. Ceci est essentiel pour filtrer les tables qui ne sont plus actives ou qui ont été supprimées, afin d'assurer que notre lineage soit à jour et pertinent.
CREATE TEMP TABLE active_tables AS (
SELECT DISTINCT table_name
FROM `project_id.dataset_id.tables_v1` t
WHERE t.table_type='TABLE' AND t.table_status='ACTIVE' AND t.is_deleted=FALSE
);Étape 3 : Gestion des requêtes utilisant des wildcard tables
Cette étape crée une table mapping_wildcards_table pour gérer les requêtes qui utilisent des wildcards (*) pour référencer plusieurs tables à la fois. Le script identifie les tables réelles qui correspondent à ces wildcards et crée un mapping entre elles.
CREATE TEMP TABLE mapping_wildcards_table AS (
SELECT l.ref_table_name, t.table_name
FROM
(
SELECT DISTINCT ref_table_name
FROM lineage
WHERE ENDS_WITH(ref_table_name, '*')
) l
INNER JOIN active_tables t
ON t.table_name LIKE REPLACE(l.ref_table_name, '*', '%')
);Étape 4 : Expansion des wildcards dans le lineage
Dans cette étape, le script étend les tables référencées par des wildcards en les remplaçant par les tables correspondantes réelles. Ensuite, il combine ces tables avec celles qui ne contiennent pas de wildcards pour former un lineage complet.
CREATE TEMP TABLE lineage_endtable AS (
SELECT
l.statement_type,
l.destination_table_name,
m.table_name AS ref_table_name,
l.insert_timestamp
FROM lineage l
INNER JOIN mapping_wildcards_table m
ON l.ref_table_name=m.ref_table_name
WHERE ENDS_WITH(l.ref_table_name, '*')
UNION ALL
SELECT
l.statement_type,
l.destination_table_name,
l.ref_table_name,
l.insert_timestamp
FROM lineage l
INNER JOIN active_tables t
ON l.ref_table_name=t.table_name
WHERE NOT ENDS_WITH(l.ref_table_name, '*')
);Étape 5 : Mise à jour de la table de lineage
La dernière étape consiste à mettre à jour la table lineage_tables_v1 avec les nouvelles données de lineage. Une colonne supplémentaire est ajoutée pour compter le nombre de fois où chaque table source a été référencée, ce qui facilitera l'algorithme de détection des tables inutilisées.
CREATE OR REPLACE TABLE `project_id.dataset_id.lineage_tables_v1` AS (
SELECT
statement_type,
destination_table_name,
ref_table_name,
COUNT(ref_table_name) OVER (PARTITION BY ref_table_name) AS ref_table_count,
insert_timestamp
FROM lineage_endtable
WHERE ref_table_name IS NOT NULL
);Algorithme de détection des tables inutilisées dans BigQuery
Ces étapes appliquent un algorithme de détection des tables inutilisées, puis listent toutes les tables avec des informations sur leur utilisation, taille, coût estimé, etc.
Étape 1 : Initialisation des variables de suivi
Dans cette étape, plusieurs variables sont déclarées pour suivre l'état de l'algorithme :
- lv_unused_table_count et lv_new_table_count suivent le nombre de tables inutilisées détectées.
- lv_max_iteration définit la limite maximale d'itérations pour éviter les boucles infinies.
- lv_iteration compte le nombre d'itérations effectuées dans la boucle.
DECLARE lv_unused_table_count INT64 DEFAULT 0;
DECLARE lv_new_table_count INT64 DEFAULT 0;
DECLARE lv_max_iteration INT64 DEFAULT 50;
DECLARE lv_iteration INT64 DEFAULT 0;Étape 2 : Création d'une table temporaire des tables actives
Cette étape consiste à créer une table temporaire active_tables qui contient toutes les tables BigQuery actives dans l'organisation. Ceci est essentiel pour filtrer les tables qui ne sont plus actives ou qui ont été supprimées. Cela sert à limiter le périmètre d'analyse aux tables encore pertinentes.
CREATE TEMP TABLE active_tables AS (
SELECT DISTINCT table_name
FROM `project_id.dataset_id.tables_v1` t
WHERE t.table_type='TABLE' AND t.table_status='ACTIVE' AND t.is_deleted=FALSE
);Étape 3 : Filtrage du lineage pertinent
Cette étape crée une table temporaire useful_lineage en filtrant le lineage pour ne conserver que les requêtes ayant effectivement alimenté des tables actives. Seules les tables de destination existantes dans les tables actives sont conservées.
CREATE TEMP TABLE useful_lineage AS (
SELECT
l.destination_table_name,
l.ref_table_name,
l.ref_table_count
FROM `project_id.dataset_id.lineage_tables_v1` l
WHERE l.statement_type IN ('SELECT', 'INSERT', 'UPDATE', 'MERGE', 'CREATE_TABLE_AS_SELECT')
AND l.destination_table_name IN (select table_name FROM active_tables)
);Étape 4 : Détection initiale des tables inutilisées
Dans cette étape, la détection initiale des tables inutilisées est effectuée. La table temporaire unused_tables_v1 est créée, contenant les tables actives qui n'ont pas été référencées comme source dans une requête, ce qui indique qu'elles sont inutilisées.
CREATE TEMP TABLE unused_tables_v1 AS (
SELECT DISTINCT
a.table_name,
0 AS layer
FROM active_tables a
LEFT OUTER JOIN (
SELECT DISTINCT ref_table_name AS table_name_used
FROM `project_id.dataset_id.lineage_tables_v1`
) t
ON a.table_name=t.table_name_used
WHERE t.table_name_used IS NULL
);Étape 5 : Propagation des tables inutilisées à travers le graphe de lineage
Cette boucle permet de propager le statut "inutilisé" à travers le graphe de lineage. Si une table n'a été utilisée que pour alimenter d'autres tables inutilisées, elle est également marquée comme inutilisée. La boucle continue jusqu'à ce que plus aucune nouvelle table ne soit détectée comme inutilisée, ou jusqu'à ce que le nombre maximal d'itérations soit atteint.
# Affecter le nombre de table inutilisées détectées
SET lv_unused_table_count = (SELECT COUNT(1) FROM unused_tables_v1);
LOOP
# Affection le nombre d'itération courant
SET lv_iteration = lv_iteration + 1;
# Propagation sur le graphe sur un niveau par jointure
MERGE INTO unused_tables_v1 t
USING
(
SELECT DISTINCT
l.ref_table_name as table_name,
lv_iteration as layer
FROM useful_lineage l
INNER JOIN unused_tables_v1 u
ON l.destination_table_name=u.table_name
/*
Condition sur le nombre de référence de chaque table source avant/après
jointure si c'est égale alors la table source n'a servi qu'à créer une
table inutilisée
*/
QUALIFY COUNT(l.ref_table_name) OVER (PARTITION BY l.ref_table_name) = l.ref_table_count
) s
ON t.table_name=s.table_name
WHEN NOT MATCHED THEN
INSERT (table_name, layer) VALUES(table_name, layer);
/*
Si le nombre de table inutilisées détectées n'a pas changé après une propagation
alors sortir de la boucle
*/
SET lv_new_table_count = (SELECT COUNT(1) FROM unused_tables_v1);
IF (lv_unused_table_count = lv_new_table_count) THEN
LEAVE;
END IF;
# Si le nombre d'itération a atteint le maximum alors erreur
IF (lv_iteration > lv_max_iteration) THEN
RAISE USING message = FORMAT("Max iteration reached.");
END IF;
SET lv_unused_table_count=lv_new_table_count;
END LOOP;Étape 6 : Création de la table finale des tables inutilisées
Une table temporaire unused_tables_final est créée pour stocker les résultats finaux de la détection des tables inutilisées, avec la profondeur (ou layer) de chaque table dans le processus de propagation.
CREATE TEMP TABLE unused_tables_final AS (
SELECT table_name, min(layer) as layer
FROM unused_tables_v1
GROUP BY table_name
) ;Étape 7 : Mise à jour de la table tables_usage_v1 avec les informations des tables inutilisées
La dernière étape consiste à mettre à jour la table tables_usage_v1 avec les informations concernant chaque table active, y compris si elle est inutilisée ou non. Cela inclut des métriques importantes comme le nombre de lignes, la taille logique et physique, et le coût du stockage. Les tables inutilisées sont identifiées avec la colonne unused et les coûts associés sont ajustés en conséquence.
CREATE OR REPLACE TABLE `project_id.dataset_id.tables_usage_v1` AS (
SELECT
t.it_organization_code,
t.project_id,
t.dataset_id,
t.table_id,
t.table_name,
COALESCE(u.layer,-1) AS layer,
(CASE WHEN u.layer>=0 THEN true ELSE false END) as unused,
t.total_rows,
(CASE WHEN u.layer>=0 THEN t.total_rows ELSE 0 END) as total_unused_rows,
t.total_logical_bytes,
(CASE WHEN u.layer>=0 THEN t.total_logical_bytes ELSE 0 END) as total_unused_logical_bytes,
t.total_physical_bytes,
(CASE WHEN u.layer>=0 THEN t.total_physical_bytes ELSE 0 END) as total_unused_physical_bytes,
(CASE WHEN u.layer=0 THEN t.total_logical_bytes / POW(2,30) * 0.01
ELSE t.total_logical_bytes / POW(2,30) * 0.02
END) as storage_price,
(CASE WHEN u.layer=0 THEN t.total_logical_bytes / POW(2,30) * 0.01
WHEN u.layer IS NULL THEN 0
ELSE t.total_logical_bytes / POW(2,30) * 0.02
END) as storage_unused_price,
CURRENT_TIMESTAMP() as insert_timestamp,
FROM `project_id.dataset_id.tables_v1` t
LEFT OUTER JOIN unused_tables_final u
ON t.table_name=u.table_name
WHERE t.table_status='ACTIVE' AND t.is_deleted=FALSE AND t.table_type='TABLE'
);Requêtes alimentant des tables inutilisées
Pour identifier les requêtes qui alimentent des tables inutilisées et avoir leur nombre total de bytes traités, nombre d’heures de slot et le prix :
CREATE OR REPLACE TABLE project_id.dataset_id.table_creation_log_v1 as (
SELECT
j.log_time,
j.statement_type,
t.table_name,
t.layer,
t.it_organization_code,
t.project_id,
t.dataset_id,
t.table_id,
t.unused,
j.capacity_reservation ,
j.total_billed_bytes,
(CASE WHEN t.unused=false THEN 0
ELSE j.total_billed_bytes
END) AS unused_total_billed_bytes,
j.total_slot_ms,
(CASE WHEN t.unused=false THEN 0
ELSE j.total_slot_ms
END) AS unused_total_slot_ms,
(CASE WHEN j.capacity_reservation='unreserved' THEN j.total_billed_bytes / POW(2,40) * 6.25
ELSE j.total_slot_ms / (1000*3600) * 0.066
END) AS price,
(CASE WHEN t.unused=false THEN 0
WHEN j.capacity_reservation='unreserved' THEN j.total_billed_bytes / POW(2,40) * 6.25
ELSE j.total_slot_ms / (1000*3600) * 0.066
END) AS unused_price,
FROM `project_id.dataset_id.raw_bq_jobs_complete_v1` j
INNER JOIN `project_id.dataset_id.tables_usage_v1` t
ON FORMAT('%s.%s.%s',j.destination_table.project_id, j.destination_table.dataset_id, j.destination_table.table_id)=t.table_name
WHERE j.statement_type IN ('SELECT', 'INSERT', 'UPDATE', 'MERGE', 'CREATE_TABLE_AS_SELECT')
);Visualisation des données avec Power BI
Pour une meilleure compréhension et communication des résultats, nous avons créé des dashboards Power BI.
Tableau de Bord sur les tables inutilisées
Ce dashboard montre le nombre de tables inutilisées, leur pourcentage, le volume de données inutilisé en pétaoctets, et le coût mensuel associé. On remarque dans cet exemple que le coût mensuel des tables inutilisées monte à 61K€, soit 30% du coût total dépensé sur le stockage BigQuery.
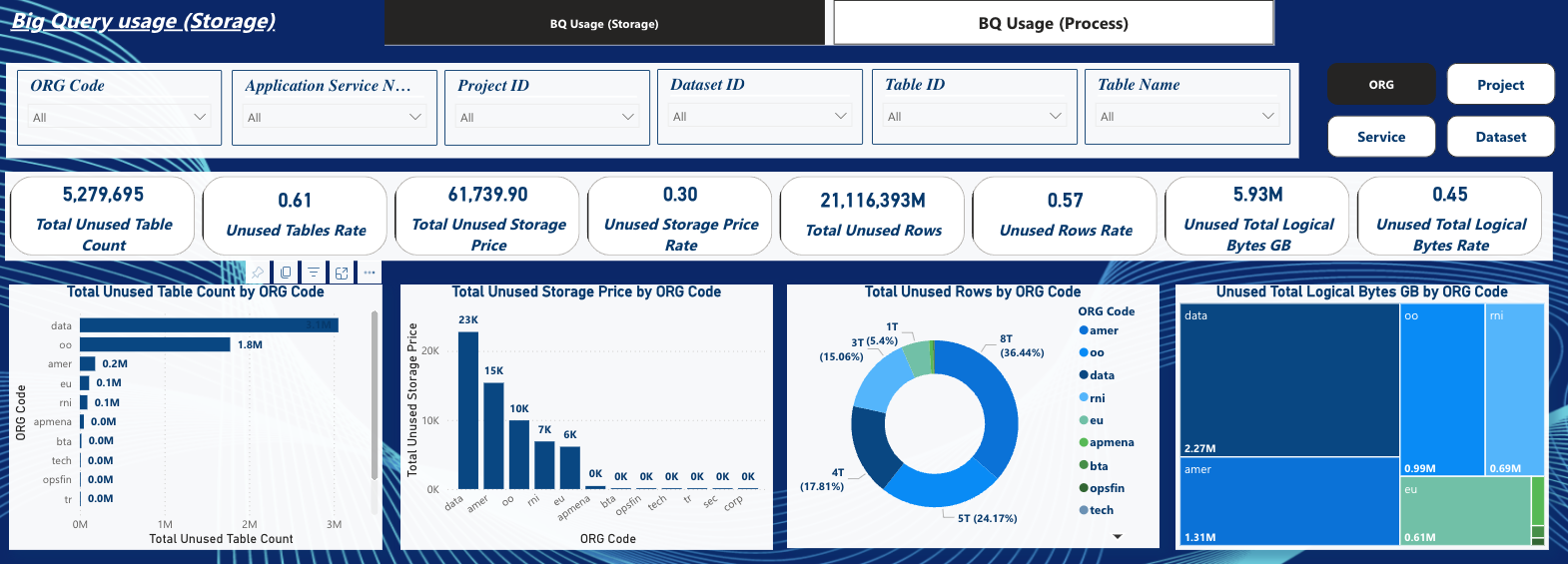
Tableau de bord sur les requêtes alimentant des tables inutilisées
Ce dashboard présente le nombre de requêtes ayant alimenté des tables inutilisées, le nombre de pétaoctets traités, le nombre de slot hour et le coût correspondant.
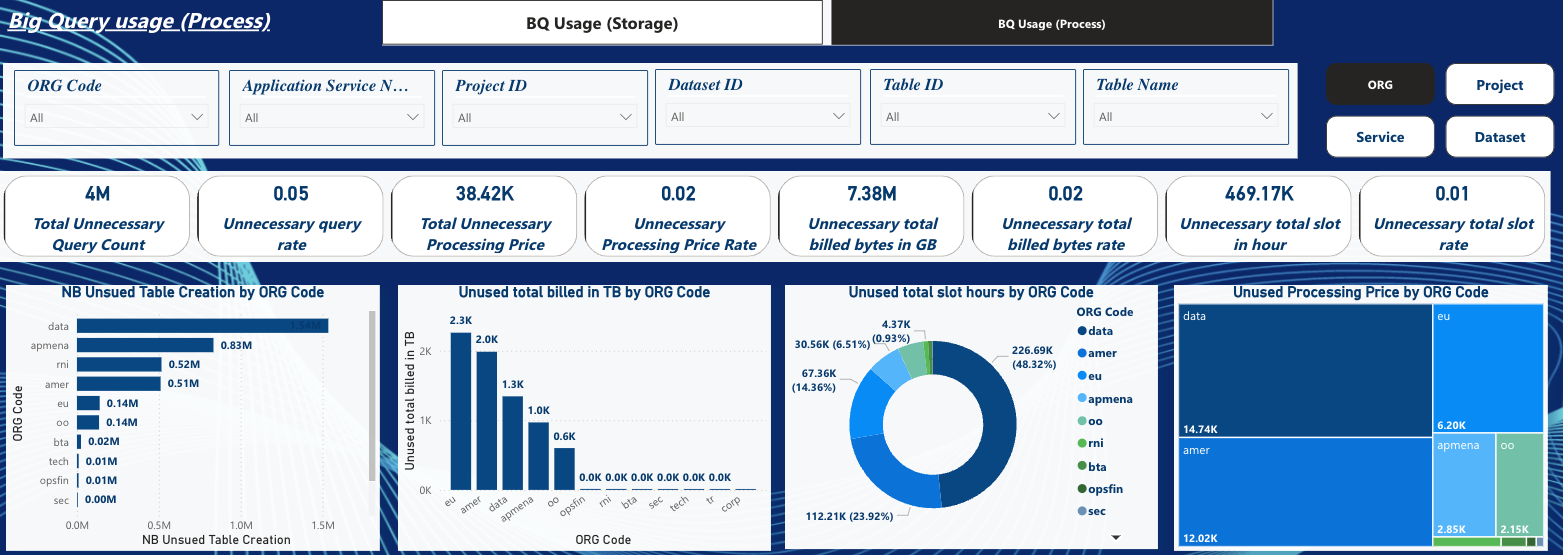
On remarque dans cet exemple que le coût des requêtes ayant servi à alimenter les tables inutilisées s’élève à 38K€ sur les 6 derniers mois, soit 2% du coût total dépensé sur les requêtes BigQuery.
En appliquant ces techniques, votre entreprise peut réduire les coûts de stockage et de traitement, tout en améliorant l'efficacité de l'utilisation des données sur le cloud.







{kind=link}